作为一只以 Django 作为主力开发框架的 CRUD Boy ,时常和它的 ORM 缠绵悱恻、纠缠不清,特此记录一下这些笑与泪的记忆。
魔鬼的陷阱
QuerySet 的类型
有时候希望它简单一点
objects.values() 返回的并不是简单类型的数据,而是 QuerySet。一般直接用来做 Response 没有问题,但是要知道 QuerySet 是不能被 pickle 的,如果使用到 Django Cache 之类功能,直接用 values() 当作返回会死得很惨。
有时候希望它坚持自我
很多时候我们需要限制 QuerySet 返回的字段以加快 DB 查询的速度(比如一些没索引的长字段),这时候可能的两个方法: only() & values() 。
但实际情况是,使用 values() 会改变 queryset._iterable_class ,如果后面还有更多的级联查询,会导致最后的结果为 Dict 而不是 QuerySet。
多对多和 values()
存在一个模型
1 | class Foo(models.Model): |
存在一条记录
1 | foo: |
values() 预期返回
1 | [ |
实际返回
1 | [ |
没有什么太好的调整办法,只能注意 + 规避,详见:
QuerySet API reference | Django documentation | Django

ORM 终究只是 ORM
我们要时刻记住, orm 只是做一个映射,有时候拿到的对象和我们预想并不能完全一致。
隐式转换
1 | class Foo(models.Model): |
通过以上的例子就能知道,我们自己创建的内存对象 f1 和通过 orm 拿出来的内存对象 f2 完全不是同一个东西,虽然他们都可以操作同一条数据库记录,但如果在内存对象里做比较就会有很多问题,比如下面的例子
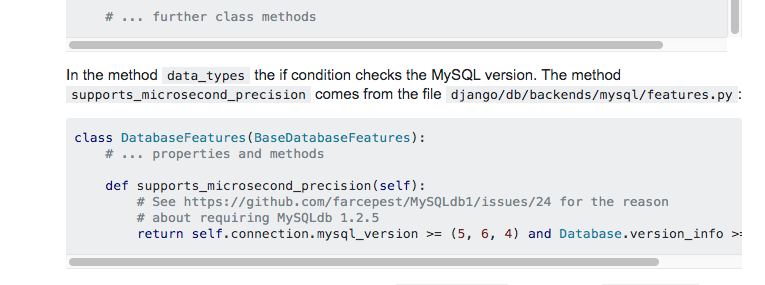
Mysql 低版本时间精度问题
1 | class Foo(models.Model): |
原因很简单,当 mysql 版本小于 5.6.4 时是不支持 microseconds 的,由于我们的 f 是内存对象,拿到的 created 又是有 microseconds 的,相当于我们在用 2020-09-18 09:24:38.260779 和 2020-09-18 09:24:38.000000 做比较, o 一直拿到的就是 f 对应的记录…
虚假的 .query
我们常常用 queryset.query 去检查复杂的查询语句,但实际上 query 属性并不能真实反应提交到 DB 中的 sql ,可以参考如下链接:
QuerySet.query.str() does not generate valid MySQL query with dates
那么如何调试提交到 DB 中的具体语句呢?
1 | from django.db import connection |
再或者,直接在 DB 中开启 general_log 。
天使的眼泪
巧用 extra
QuerySet API reference | Django documentation | Django
extra() 可以利用 sql 在数据库中做数据处理,而不用放到内存中,在数据量较大时有比较好的效果,比如:
1 | queryset = queryset.extra(select={'username': "CONCAT(username, '@', domain)"}) |
在模糊查询时,匹配最短结果
1 | MyModel.objects.extra(select={'myfield_length':'Length(myfield)'}).order_by('myfield_length') |
但在同时需要格外小心, extra() 在参数上存在注入风险,所有可能的用户输入的 SQL 拼接,都应该交给 Django 处理。
1 | # 有注入风险, username 不会被转义,可以直接注入 |
JsonField 的福音—— JSON_SEARCH
有时候我们需要使用动态字段,并且保证动态字段的值全表唯一。动态字段我们使用 LONGTEXT 存储,格式为 JSON 。如果手动处理,需要将整个表的字段放到内存,并做唯一校验,非常麻烦且耗时。
所以还是一个道理,把这个逻辑交给 DB
1 | select * from profiles_profile where JSON_SEARCH(extras, "one", "aaa") is not null; |
行锁的支持
多个操作互斥的情况下,可以使用 select_for_update 行锁保证正确性。
1 | with transaction.atomic(): |
但是同时需要注意,上锁的顺序,避免产生死锁。