
What ?
Profiling vs Continuous Profiling
相信各位开发老司机都给自己的程序“号过脉”,所以对于 Profiling 一定不陌生,在这里我还是搬一下 Profiling 的定义:
Profiling 是一种性能分析工具,用于确定程序或系统中哪些部分消耗了最多的资源(例如 CPU、内存、磁盘和网络)。它可以帮助开发人员找到性能瓶颈并改进代码。
而 Continuous Profiling 就是在这个基础上,增加一个“持续”,也就是在生产环境里定期跑 Profiling 并将数据上报。
通常开发者手动跑 Profiling 往往是发现了线上代码性能瓶颈后,用工具尝试复现瓶颈,而 Continuous 最大的优势就是:持续意味着贯穿整个程序的完整生命周期,不会漏掉任何一个历史上产生过的异常,能直接从数据中找到“现场”,而不是尝试复现。
用一个非常直观的比较就能迅速理解二者的差异:如果 Profiling 最有代表性展示方式是火焰图的话,那么 Continuous Profiling 的表现形式就是带有时序功能的火焰图,你可以在拖动展示、对比不同时刻的火焰图,找到代码在时间维度上的性能变迁。
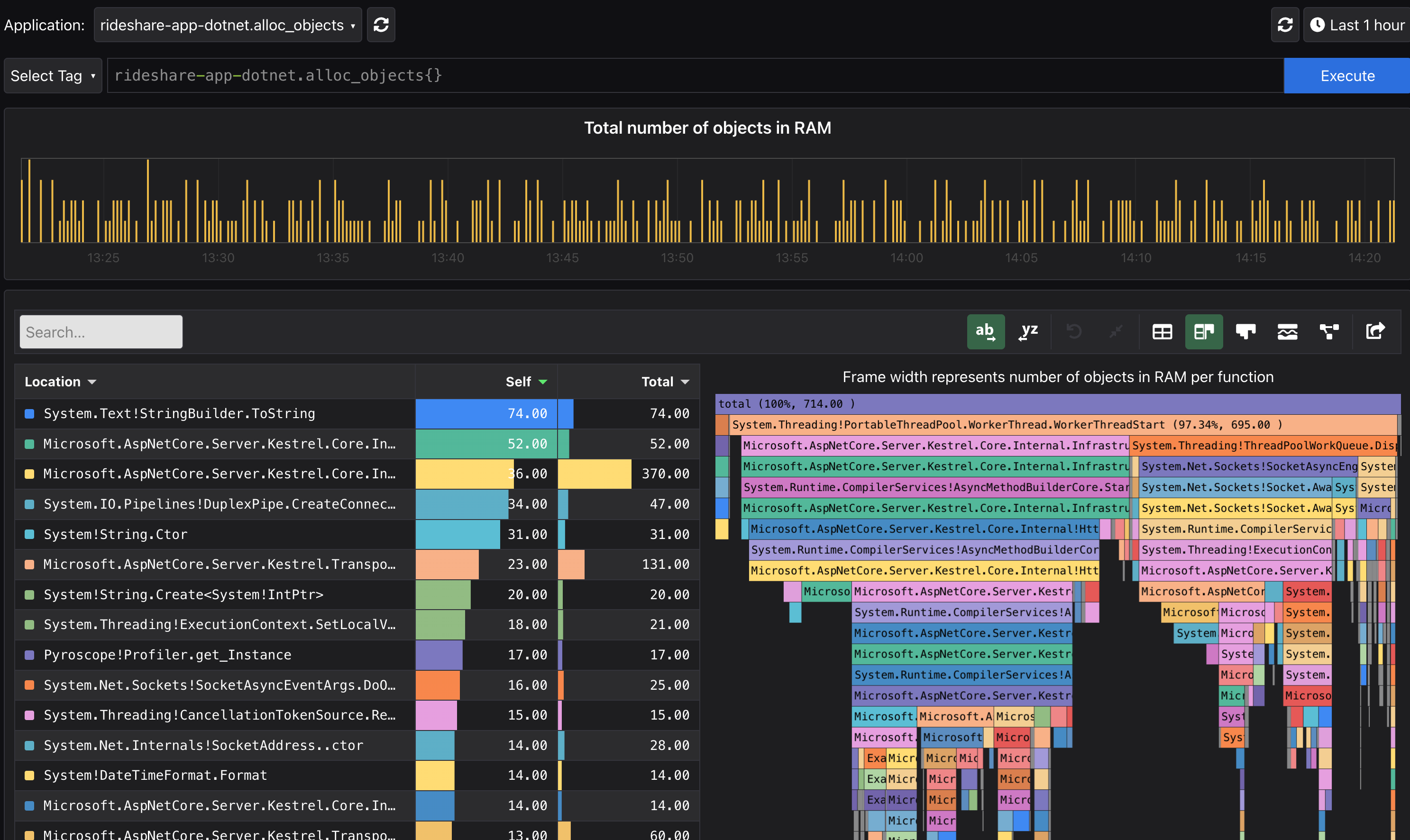
一个典型的例子
来龙
Continuous Profiling 这个概念最早出自 Google 2010 年的研究文章: Google-Wide Profiling 。它虽然没有直接输出可用的工具,但是却给这个理念“打了样”:以较低的开销(~0.01% Overhead) 换取了大量对生产有用的代码状态数据,并且通过类 SQL 的方式查询以定位问题。
去脉
转眼到了十多年后,这期间有不少开源或商业软件涌现,但 OpenTelemetry 的加入给了 Continuous Profiling 领域一个确定的未来。
“Four pillars”
在 Monitoring, Logging, Tracing 三大支柱的工具链逐渐完善后,Profiling 将成为可观测领域新的支柱。
Why ?
借用 OT Profiling Vision 里列举的一些场景:
- 跟踪应用程序的资源利用情况,以了解代码更改、硬件配置更改和临时环境问题如何影响性能
- 理解哪些代码负责消耗资源(例如 CPU、内存、磁盘、网络)
- 为在生产中运行的一组服务规划资源分配
- 比较不同代码版本的配置文件,了解代码如何随时间改进或退化
- 在生产中检测经常使用的和“死”代码
- 将跟踪跨度分解为代码级粒度(例如函数调用和代码行),以了解该特定单元的性能
简而言之,Continue Profiling 可以帮助开发者掌握代码的“持续生产状态”。对于 DevOps 团队而言,它应该是 CD 后进行持续分析的一部分。
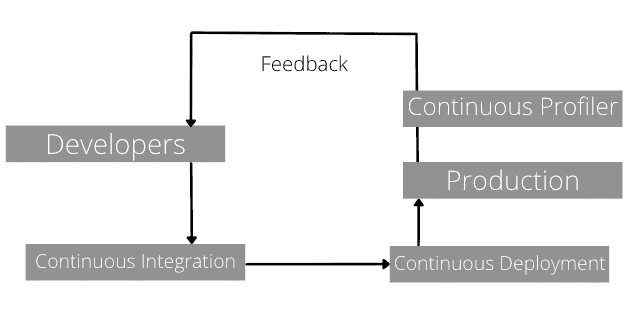
CI → CD → CP
开源方案
Pyroscope
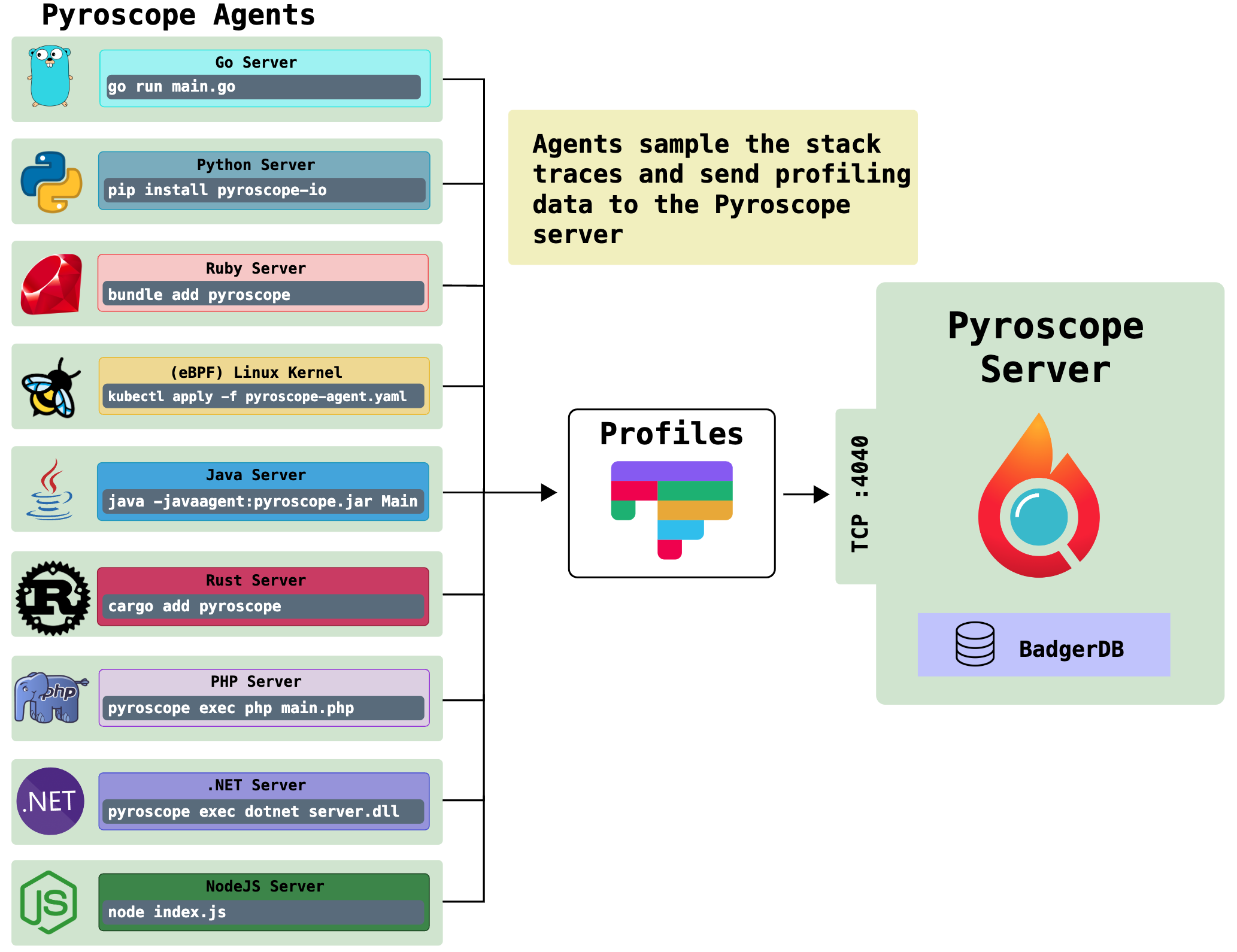
架构图
Pyroscope 项目算是这个领域中最热门的种子选手了。相较于其他几个项目有这么几个显著的优势:
- UI 清晰美观,功能齐全,可以从官方提供的 demo 窥见一二
- 支持的语言广泛
- 支持 Go\Java 的 Tracer 整合方案
- 对存储有着额外的优化
下面会针对一些有特点的优势展开说说:
语言支持
上面有提到,Pyroscope 对于 pull 和 push 模型都有着完备的支持,最大的原因就是它针对各个语言的采集工具上都做了适配,并封装成了 SDK:
- Go: pprof
- ruby: rbspy
- python: py-spy
- Java: async-profiler
- php: phpspy
- .NET: dotnet trace
- Rust: pprof-rs
即使部分语言的支持并不完美(例如 Python 不支持 Memory 数据上报),但鉴于其他项目基本都只支持 Go + pprof,在面临多语言环境时,Pyroscope 基本是开源的唯一选择。
存储优化
与其他几个项目还有一个很大的不同,pyroscope 在 profiling 数据的存储上做了额外的优化,开发者专门写了一篇 Blog 介绍了思路。在这里做下简要的介绍并分析。
首先是借助树和字典树,它针对 Profiling 的重复数据做了压缩。

其次,为了解决长时间跨度数据的查询延迟问题,利用线段树对数据进行了预合并。
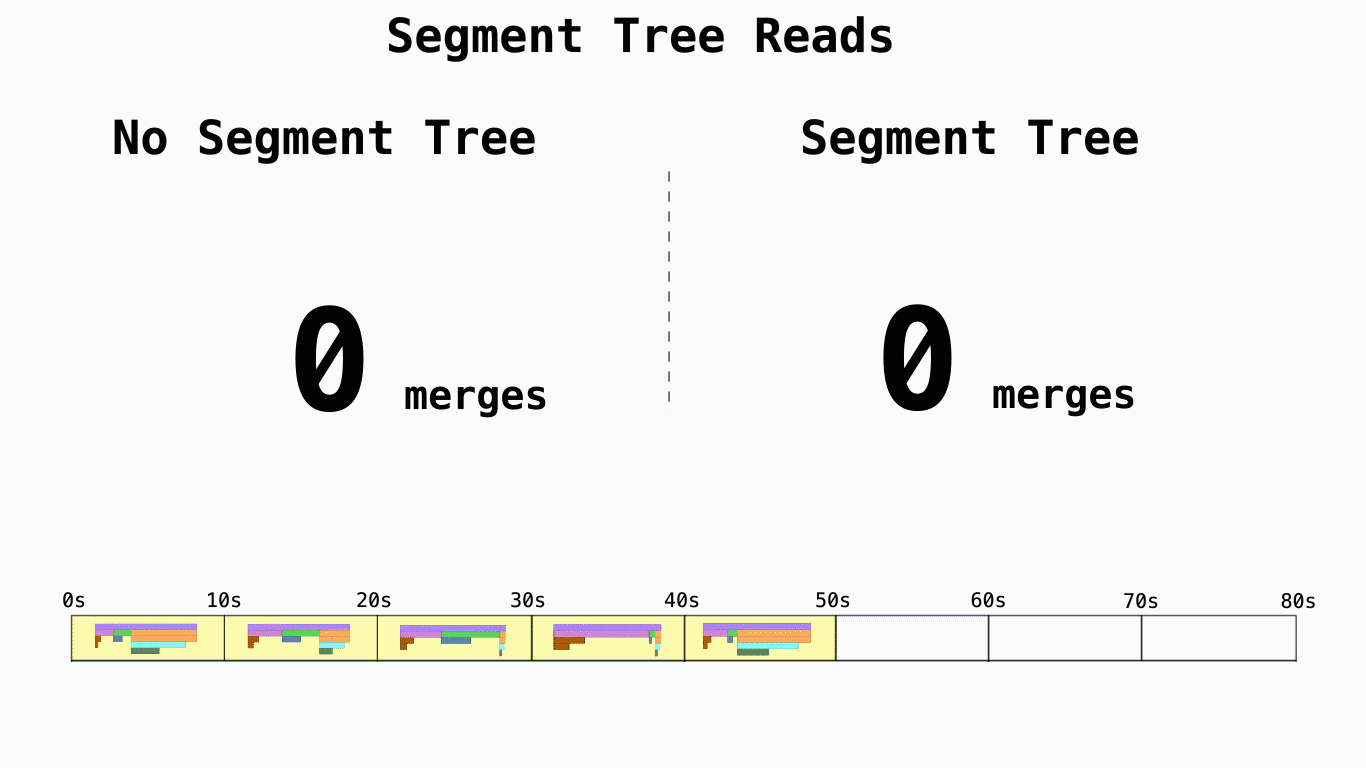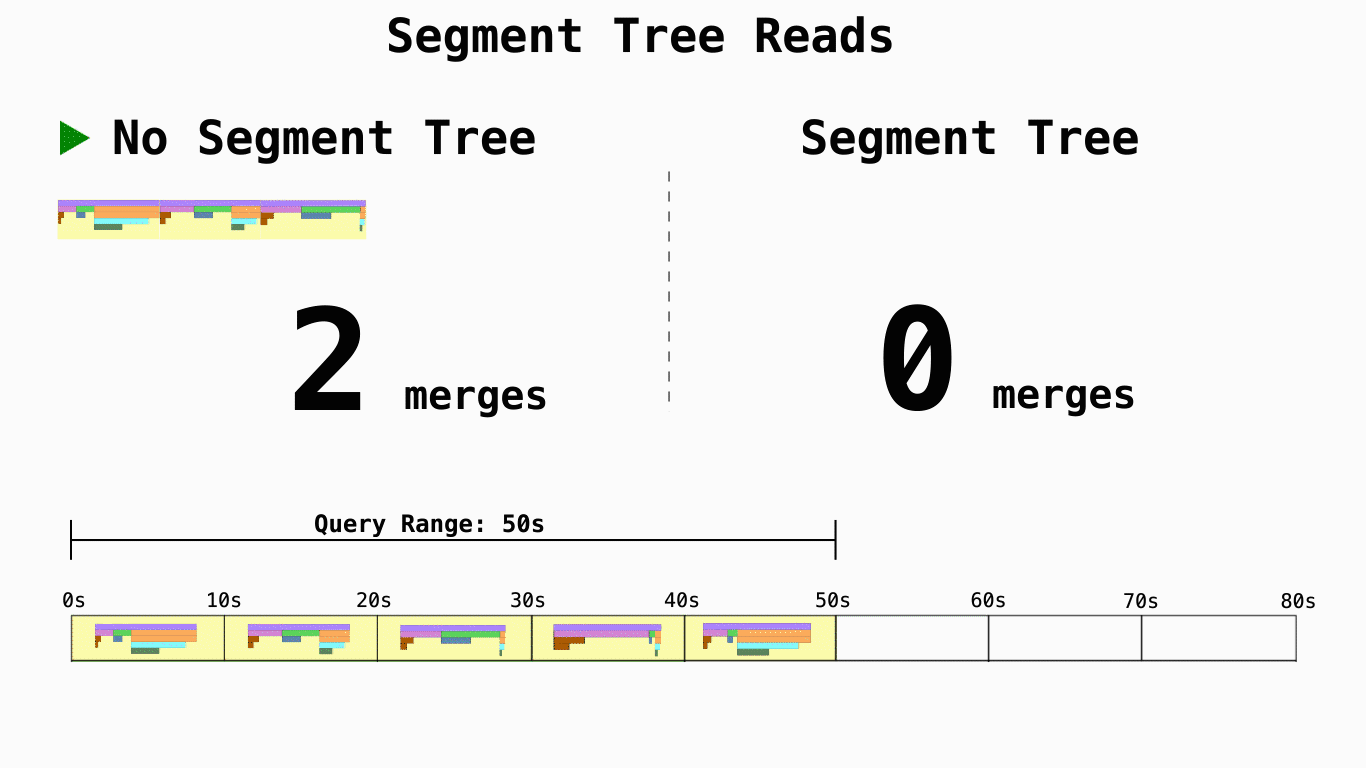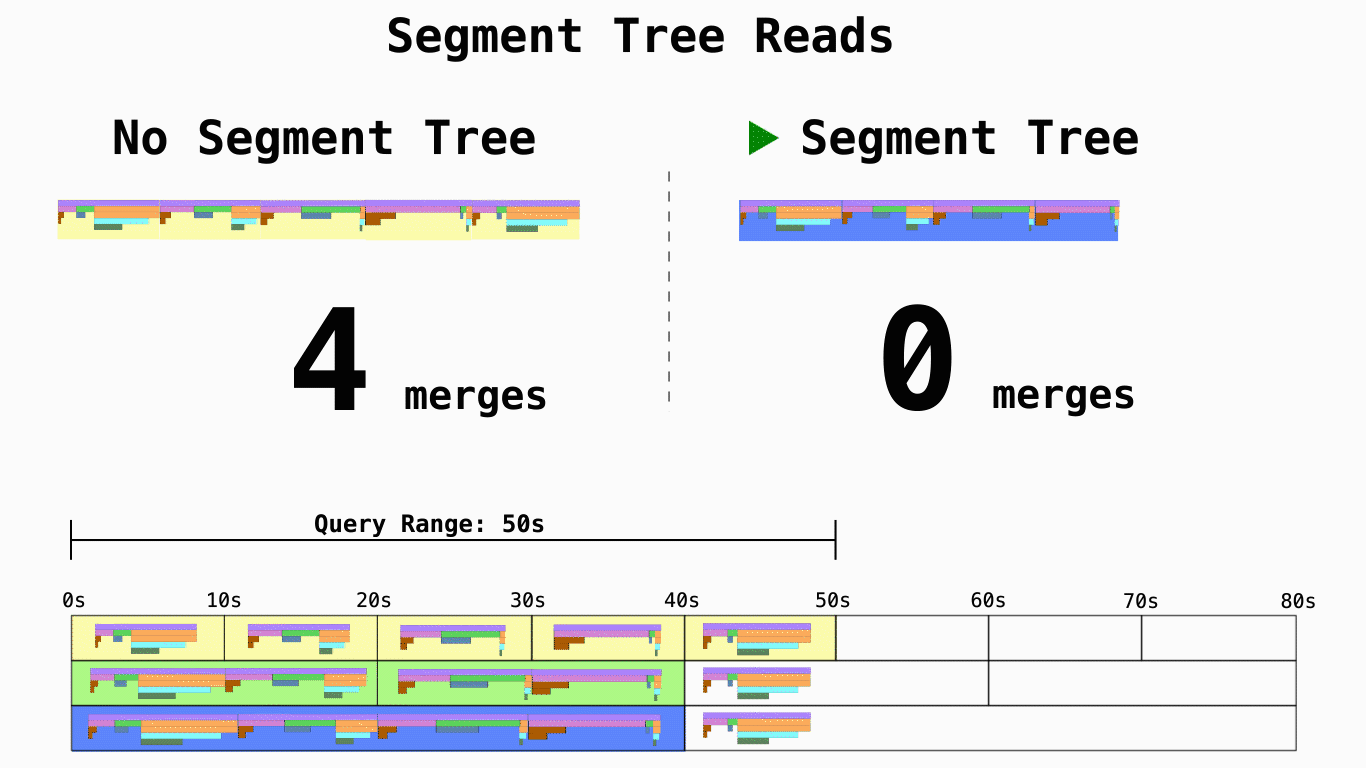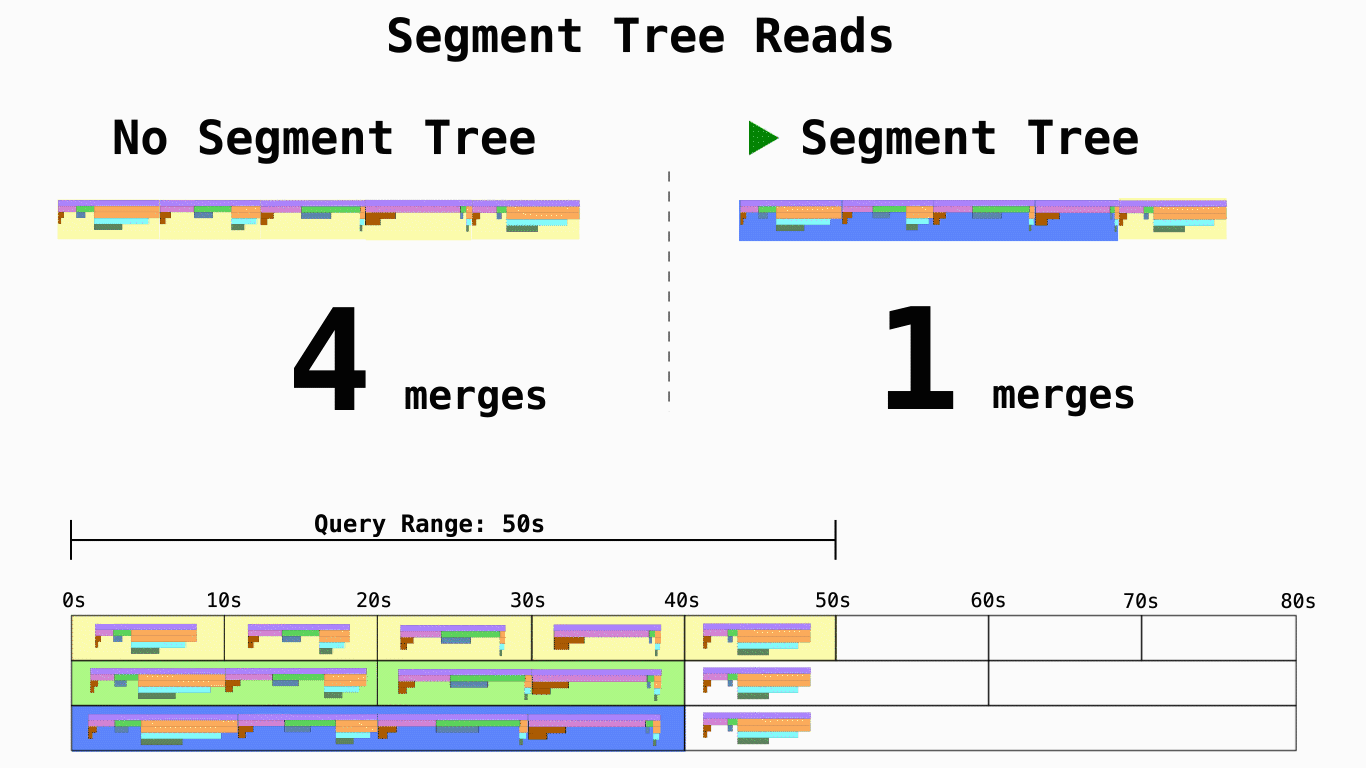
虽然和其他项目一样,它的存储逻辑模型基本依照 pprof 定义,得益于这些优化,它在存储空间和读取延迟上都有更好的表现。但也带来了一些其他的问题:
- 为了更容易实现这些优化,存储引擎选择了灵活的 K-V 结构内嵌引擎 BadgerDB,也因此失去了更好的水平扩展能力。
- 在结构落库时需要消耗更多的 CPU 计算,压测时 CPU 更容易出现瓶颈。
总结
Pyroscope 绝对是 Profiling 领域的开源种子选手,它的长板很长(语言支持、存储优化等),同时考虑到最近被 Grafana Labs 收购,原来的短板恰好是 Grafana 团队擅长处理的,相信等待一段时间的发展,Pyroscope 有潜力成为该领域的开源标准答案。
Parca

Parca 项目是由原 Prometheus 团队的开发者开发,带有浓浓的 Prometheus 的味道。相较于其他项目,它也有几个显著的特点:
- Agent 完全采用了 ebpf 作为采集方案
- Profile Meta 和 Profile Sample 使用了两种不同的引擎存储,其中 Sample 存储采用了自研的内嵌列存 FrostDB
eBPF Agent
近几年 eBPF 在云原生、可观测领域讨论度很高,相信紧跟热点的各位读者也是早有耳闻,我在这里就不做多的赘述。Parca 最显著的一个特点就是在 Agent 上完全使用 eBPF 来解决问题。以下是一个简化的处理流程:

在 Profiling 领域,eBPF 的优劣我们会在后面的章节谈到,这里就一笔带过了。
Meta Sample 分离存储
Parca 和其他项目一样,存储的逻辑模型也是依照 pprof 的数据定义,而 pprof 逻辑模型中,按照其不同的特性,可以划分为两类数据:Meta 和 Sample。所谓的分离存储,实际上是讨论:这两类数据是否使用不同的存储引擎。
| 类型/特性 | 具体内容 | 是否需要计算 | 数据量级 |
|---|---|---|---|
| Metadata | Function/Mapping/Location 等 | 很少 | 较小 |
| Sample | 时序的 Stacktrace | 大量合并计算 | 大 |
由于以上特性,二者的读写需求也不同,所以顺其自然的想法就是将其分成不同的引擎存储。
| 方式/特性 | 开发便捷性 | 后期存储维护性 | 存储引擎选择空间 |
|---|---|---|---|
| 统一存放 | 高 | 一般 | 一般 |
| 分离存放 | 较低 | 高 | 高 |
相较于后期的维护性,开发便捷性的损失是一次性且短期的,且不分离的情况是不太方便针对二者特性做针对性优化的。所以 Meta / Sample 分离存储,对于服务的“长治久安”有着更好的积极意义。当然 Parca 目前在 Sample 存储上使用的 FrostDB 还未到可以直接生产的阶段,目前仅是 Parca 专用内嵌引擎。
总结
Parca 项目在 Agent 选择和存储设计上有独到之处,虽然在语言支持上比较少(Go 和有限的 Java),但仍旧可以作为方案设计上的重要参考。
Phlare
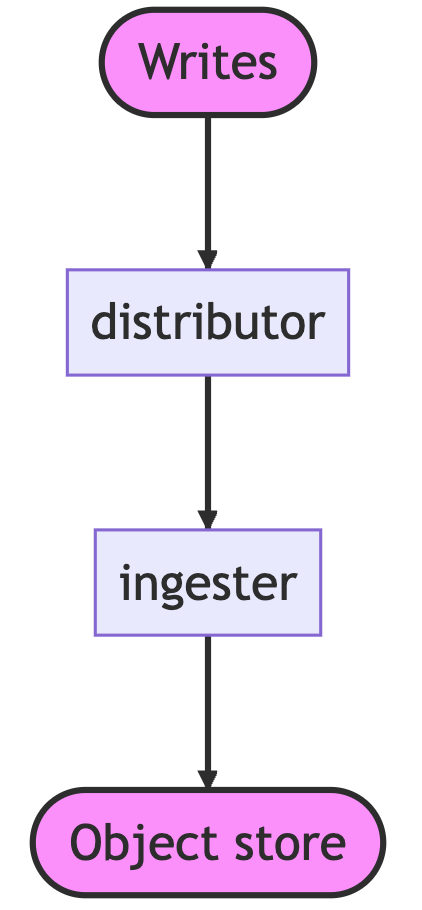

Phlare 是 Grafana Labs 出品的 Profiling 产品,随着 Pyroscope 被收购,Phlare 项目很可能会被直接揉碎,合并到 Pyroscope 中去。即便如此,Phlare 项目仍旧有着不少有意思的亮点:
- 支持 monolithic/microservices 两种启动模式,既能满足快速验证,又能在大规模部署中轻易水平扩展
- 数据存储分层,热数据存放在 ingster 的本地块存储中,冷数据发送到远端的对象存储中,总占有成本 TCO 较低(当然是存储空间的,没有考量到对象存储发送带来的带宽成本)
水平扩展
相较于 Parca 和 Pyroscope,Phlare 总算把工程的扩展能力当作重要考量了。要知道前面二者想要水平扩展,无论是想扩展读或者写的能力,都只能将整个进程跑起来,存储走 remote write 的方式,既笨拙又浪费资源,难称优雅。而 Phlare 具备以微服务部署的能力,qureier 和 distrubutor 可以较轻松地水平扩展。
- 在存储上通过一致性哈希解决分片问题
- 通过 Gossip 解决分布式选主问题
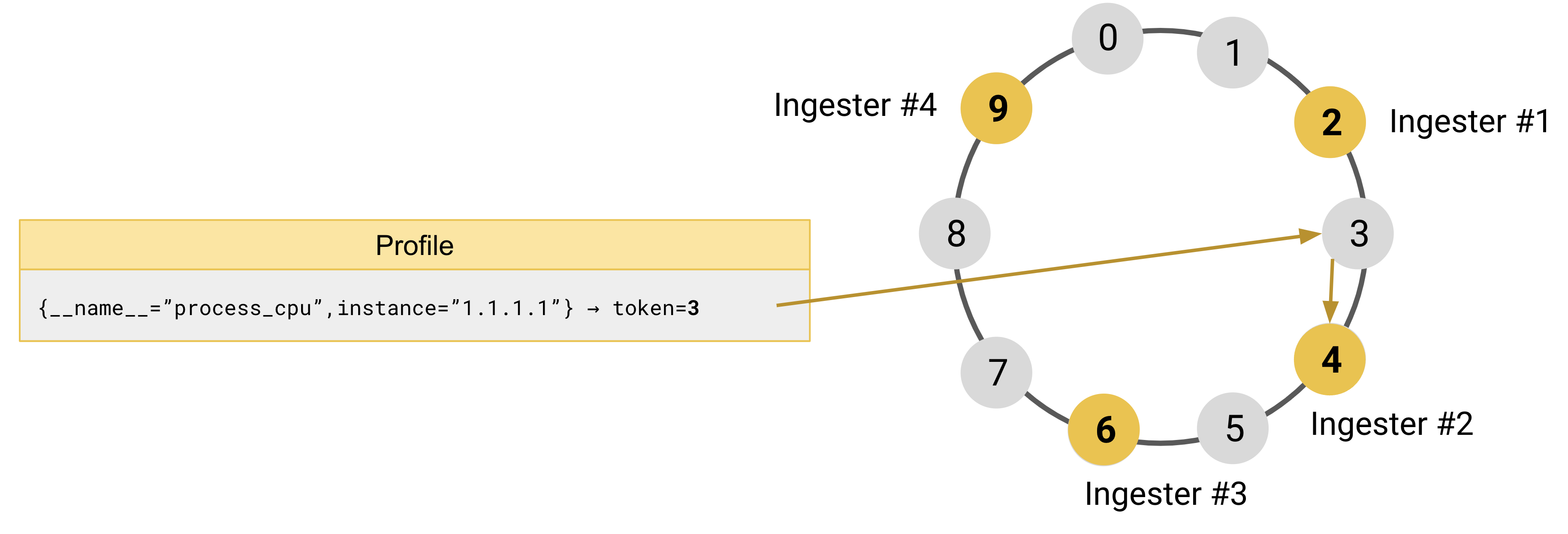
为了更好地理解它是如何工作的,以四个 ingester 和一个位于0和9之间的令牌空间为例(来源):
- ingester#1在令牌环中注册令牌
2 - ingester#2在令牌环中注册令牌
4 - ingester#3在令牌环中注册令牌
6 - ingester#4在令牌环中注册令牌
9
当它接收到一个带有 label {**name**="process_cpu", instance="1.1.1.1"} 的 Profile 数据时,它会将 label 内容进行哈希计算,假如这次计算后的结果是 3 。为了找到对应的 ingester,将会尝试寻找哈希环上 token 值上大于 3 最靠近的一个,即 ingester#2,并认为它将是这份 Profile 的权威数据拥有者。
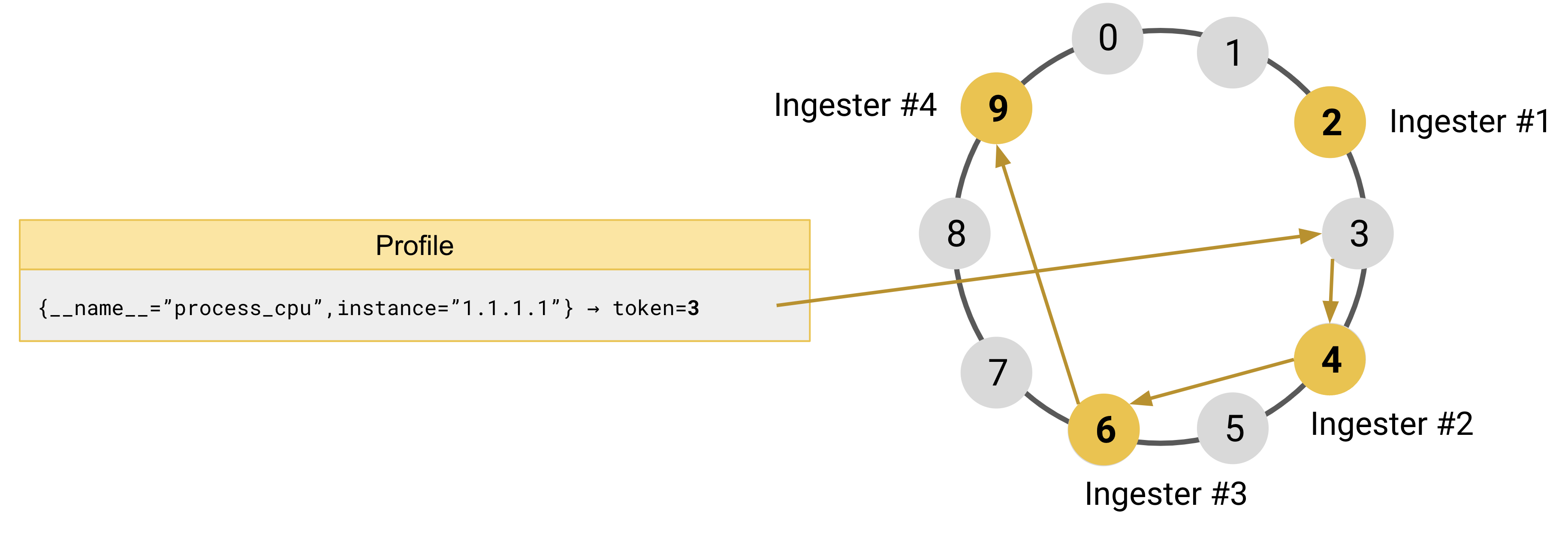
此时, Ingester 的副本数设置如果是 3 个,在 ingester#2 被选主后,将继续向后寻找接下来的两个实例,即 ingester#3 & ingester#4,并将数据复制分摊到他们的存储中,以保证数据能够均匀地被复制成多副本来保证高可用。
分级存储
phlare 的存储流程较为复杂,主要分成了三个部分:
- head block,ingester 模块获取到数据后不会立即写入到长期存储中,而是首先放在内存
- 当 head block 大小超限或者超时,会将这些数据写到 ingester 本地磁盘
- 内存和磁盘的数据都将会周期上报到 Long term storage
这样做的好处显而易见:
- 最热的数据将在内存中被访问,速度最快
- 大量的冷数据放到了对象存储,成本更低
但也有些问题,就像上面 read path 中表述的,对象存储中冷数据的读取问题会存在延迟问题,后面在对象存储和块存储的对比环节会稍微展开。
总结
Phlare 相较于 Parca 和 Pyroscope 增加了更多工程上的探索,它比后两者都更容易在大集群中部署和扩展,但它只支持 pprof Http 端点数据拉取,仅有 Go 能够被较好的支持,这也成了它没法被大规模采用的最大障碍。在 Pyroscope 被收购后,Phlare 的这些工程特点也许会被整合到前者里去,就让我们继续关注接下来会发生什么吧。
Pixie
pixie 实际上并不是一个 Profiling 专用软件,而是一个 K8S 应用的观测工具。除了 Profiling 以外,它还包括了Service 映射、集群资源、应用流量等能力。我们这里仅关注它的 Continuous Profiling 能力。
相较于以上其他开源软件,它又有一些不同的特点:
- PxL,用于查询 SQL 不再是 PromQL like 而是 Python 风格
- 与 K8S 集群绑定较强,不适合部署在物理机的服务
- 底层使用 eBPF 采集数据,编译型语言支持更好
- 仅限于 CPU Profiling
由于它在 Profiling 领域着墨不多,功能也相对简单,这里就不做过多展开了。
商业软件
Datadog Continuous Profiler
Datadog 作为可观测的商业 SaaS 产品巨头,推出的 Profiler 产品质量非常高,由于它的闭源性,我们很难分析它具体的技术架构,仅从它产品表现来窥见一二。
以下是一些 Datadog 有别于开源产品的亮眼功能。
可以细粒度控制 function 展示内容
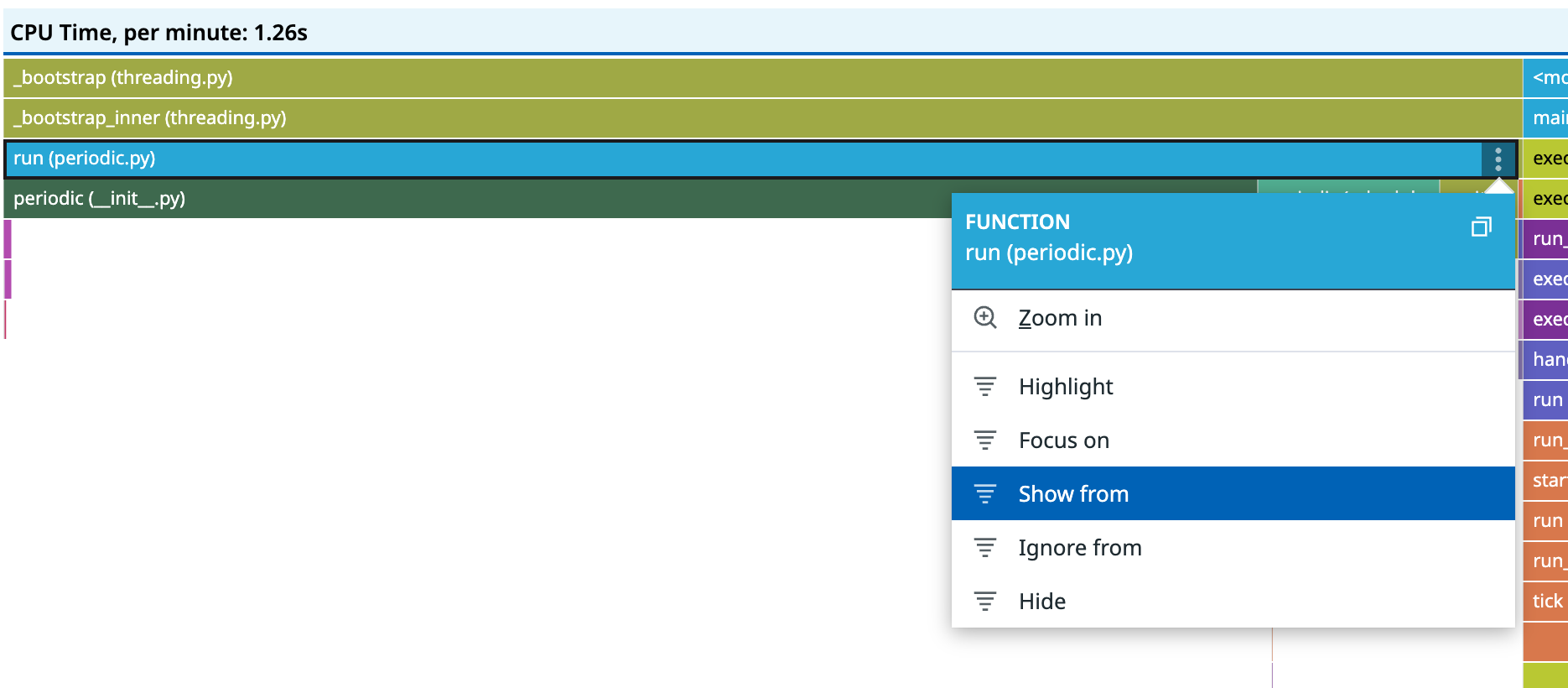
Only My Code 可以聚焦于用户代码
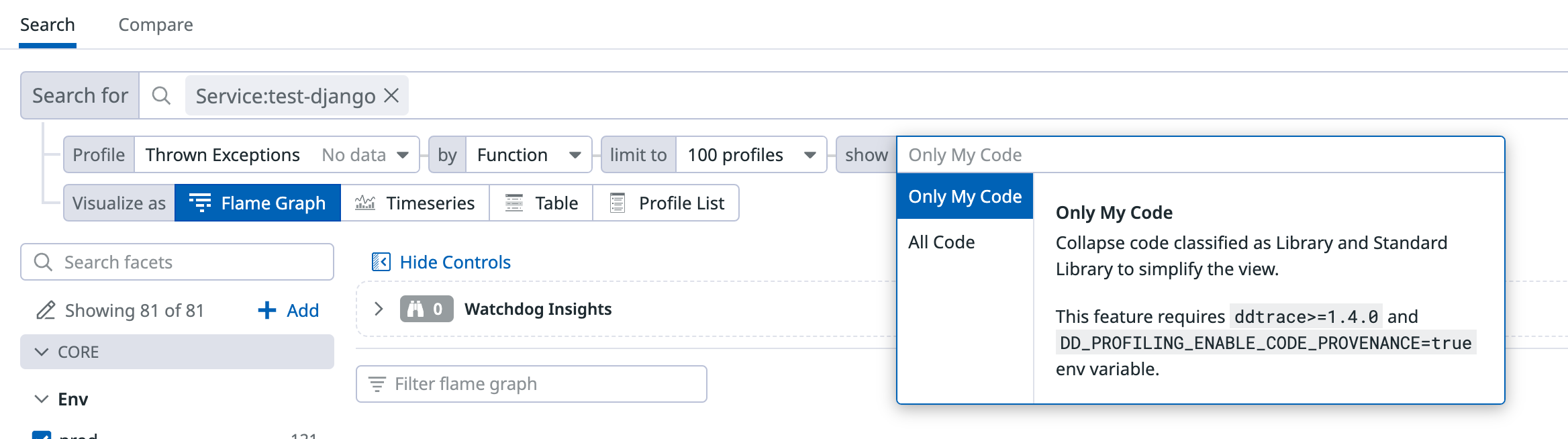
聚焦前
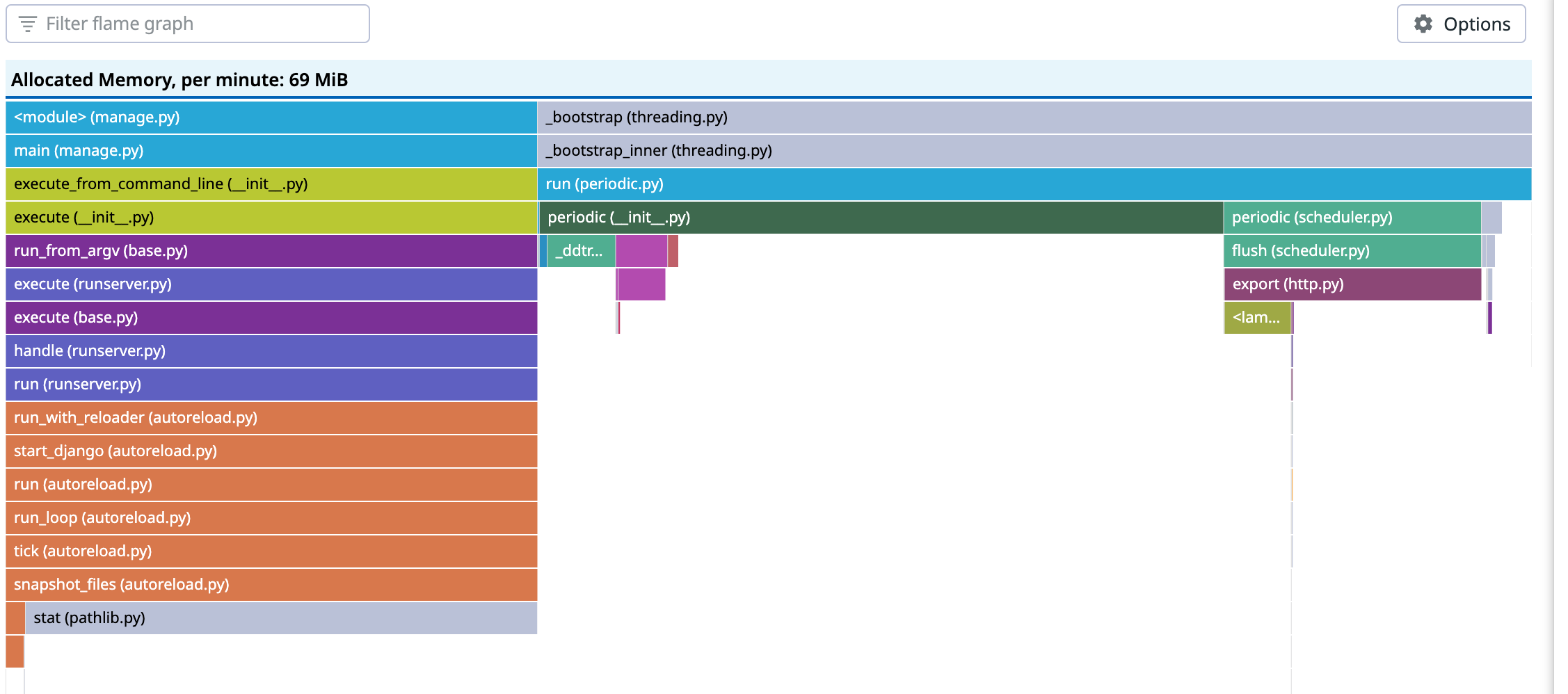
聚焦后

对比图表直观清晰
对比视图,通过颜色能够清晰获取不同时间的代码内存申请的异同。火焰图表现:
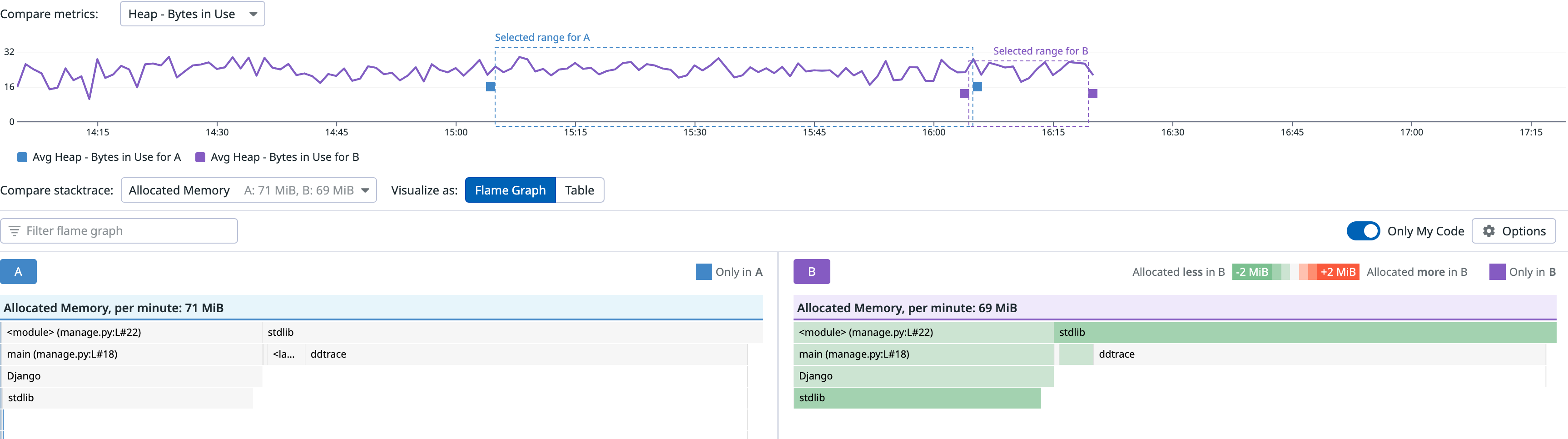
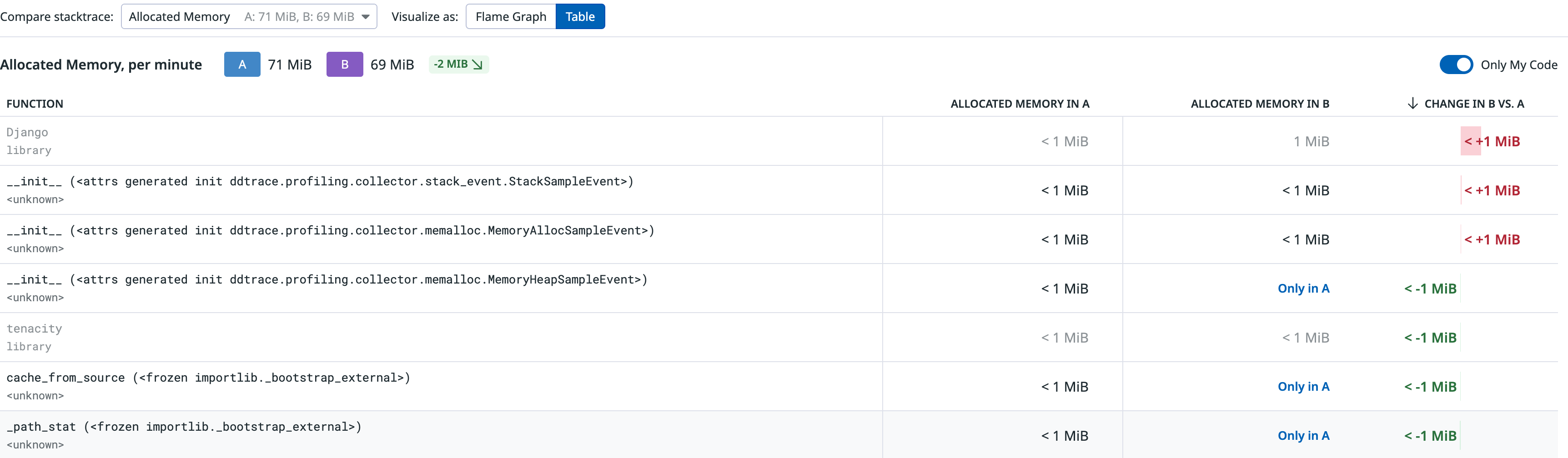
表格表现:
常用的数据聚合快捷入口
在 CPU 数据上,已经根据不同纬度提供了聚合计算快捷入口。
Elastic Profiler?
实话实说,实际上在本文写成的时候,笔者尚未体验过 Elastic Profiler ,这里就暂不置评,留空日后补充。
方案选型对抗赛
推 vs 拉
在可观测领域,数据获取的方向一直是热议的话题,Profiling 也不例外。以下是概要性的对比:
| 对比特性 | pull | push |
|---|---|---|
| 配置方式 | 原生中心化配置 | 端上配置,通过配置中心支持中心化 |
| 监控对象发现 | 依赖服务发现机制 | 由应用、Agent自主上报,无需服务发现模块 |
| 部署方式 | 应用暴露端口,接入服务发现,原生支持Pull协议 | 1. Agent 统一代理抓取 2. 应用主动推送到监控系统 |
| 指标获取灵活性 | On Demand按需获取 | 被动接受,需要一些过滤器额外支持 |
| 应用耦合性 | 应用与监控系统解耦,应用无需关心对端地址、错误处理等 | 与应用代码耦合 |
| 安全性保证 | 工作量大,需要保证应用暴露端口的安全性,容易被DDos攻击或者出现数据泄露 | 难度低,ingest 接口交互一般都有鉴权控制 |
与 Prometheus 稍有不同的是,Continuous Profiling 基本不存在短任务数据上报的场景——既然都是 Continuous 了,那肯定不短,所以 pull 场景中最大的短板——难以适配短任务——基本不存在了。同时,由于 Go 语言是该领域的绝对“第一公民”,其标准库就支持的 pprof 模块能够以极低的开发成本添加 pprof HTTP 端点,所以三大开源软件在 pull 方向的支持上都是完备的,而 push 方向除了 pyroscope,其他项目均有不同程度的“残缺”。考虑到 OT 和其他语言工具转换 pprof 的进度,这种“重 pull 轻 push” 的现象仍将在 Profiling 领域持续一段时间。
存算分离 vs 存算一体
Profiling 项目最大的技术难点就是如何处理存储,这也是可观测领域一直以来的重点。其中存算分离和存算一体的选择,决定了存储引擎乃至整个产品的形态。
在我们上面分享的几个开源产品中,它们无一例外都选择了内嵌式——也就是存算一体的方式,无论是性能较好、灵活度较高、但缺少水平扩容的 BadgerDB,还是列存 FrostDB,存取逻辑都是和计算进程绑定在一起。
在我看来,产品的服务形态是存算分离与否的决定性因素。
| 服务形态/存储类型 | 选择存算一体(内嵌存储引擎) | 选择存算分离(分布式存储服务) |
|---|---|---|
| OSS | 少依赖,易部署 👍 针对性优化灵活 👍 |
额外依赖,数据优化灵活度低 👎 |
| SaaS | 扩展、灾备方案不完善 👎 | 将状态向存储侧转移,组件复杂度相对低 👍 针对性优化难度稍高 👎 |
总而言之,产品的服务形态将很大程度上决定存储的模式。如果是偏向于 OSS 分发,选内嵌存储,如果是以 SaaS 服务为主,选专用的分布式 DBMS。当然,从具体的工程实现来说,完全可以在存储上加一个可插拔的抽象层,以适配不同的服务形态,类似这里的讨论。
块存储 vs 对象存储
在存储领域,块存储和对象存储都是非常常见的方式。
块存储(Block Storage)是将存储数据分为固定大小的块进行存储,适合于需要低延迟、高性能、高可用的场景,如数据库、虚拟机、容器等。块存储一般使用本地存储或网络存储,操作系统可以使用块设备访问。缺点在于扩展性差、价格相较于对象存储更贵,不适合存储海量数据。
对象存储(Object Storage)则是将数据存储为对象,每个对象都有唯一的标识符(URI),将数据分散到多个节点上,通过分布式算法实现高可用和容错,适合于海量数据存储和分布式存储。缺点在于读写性能较差,不适合要求低延迟和高性能的场景。
在实际 Profiling 场景下,通常会有两部分数据:
- 近期需要频繁访问的短期热数据
- 可能会存在较长时间的冷数据
从原理上来说,热、冷数据应该分别存放到块存储和对象存储中,类似上面提到的 Phlare 方案,而不是一股脑放到块存储(Pyroscope OSS 的做法)或者全部放到对象存储(好像也没人这么做)。
即使 Phlare 的方案看起来很合理,但它依旧是内嵌型存储,目前还没有一个比较成熟的分布式 DBMS 支持这样的特性。Pyroscope 在其云服务中也放弃了原来的内嵌式 K-V 存储,而转向了借用 Parquet 的分布式存储 Tempo 方案(来自其 blog),在保证后端存储针对性优化的同时,利用类似 Thanos objstore 的方案实现了利用对象存储的扩展能力,遗憾的是尚未将这部分代码开源,也无法研究其内部细节了。
eBPF vs Native Language Tools
Profier 是 Profiling 数据来源的基础,上述不少产品中都采用了 eBPF 作为采集方案,那么是否只要使用了 eBPF 就代表着开销更小、数据更全呢?并不全是,Pyroscope 的这篇 blog 给了我们一个比较客观的对比。首先从数据来源的层级来看,可以将 Profiler 分为两类:
- 用户态: 流行的性能分析工具,如pprof,async-profiler,rbspy,py-spy,pprof-rs,dotnet-trace等,都在这个层面上运行。
- 内核态: 基于 eBPF 的各种 Profiler 封装和 Linux perf 工具可以从内核获取整个系统的堆栈跟踪
由于数据来源的层级不同,它们各有长短。
对于用户态的工具而言:
- 可以非常灵活的标记用户的应用代码(例如 标记 spans, controllers, functions)👍
- 能够分析代码的各个特定部分(例如 Lambda 函数、测试套件、脚本)👍
- 有着更容易分析其他类型数据的能力(例如内存、goroutines)👍
- 本地开发十分便捷,容易使用 👍
- 复杂,如果一个系统是多语言的,很难获取一个全局视图 👎
- 对于基建元信息的标识能力有限(例如 Kubernetes) 👎
对于内核态的工具而言:
- 非常容易就能获取到跨语言的全局视图 👍
- 很容易对基建元信息进行标识能力有限(例如 Kubernetes Pods) 👍
- 所有语言在符号化上都是一致的 👍
- 对 Linux 内核版本有要求 👎
- 用户层级的代码比较难标记 👎
- 内存、goroutines 很难获取对应数据 👎
- 开发者想在本地开发比较困难 👎
- 解释器型的语言获取的信息较为有限 👎
简单来说,这两种方案的方向是反的:自下而上和自上而下,它们的数据信息理应做到互相补充,现阶段仅有 Pyroscope 对它做了有限的整合优化,需要进一步关注进展。
pprof vs OT
pprof 本身是一个开源的性能分析工具套件,它可以抓取并组装 CPU、内存、goroutine 等性能数据,并且通过配套的工具可以生成各种可视化视图,例如火焰图、调用图等。
同时 pprof 也定义了相关的 Profile 数据格式,以 Protocol Buffers 呈现。它由一系列的记录 Sample 组成:包含了函数调用堆栈以及相应的计数器值。
以下讨论的 pprof 指的是其代表的数据格式。
可以通过它的文本表达示例或者下面这张图理解其中的关联关系(除了 Stacktrace 是额外抽象出来的中间表)
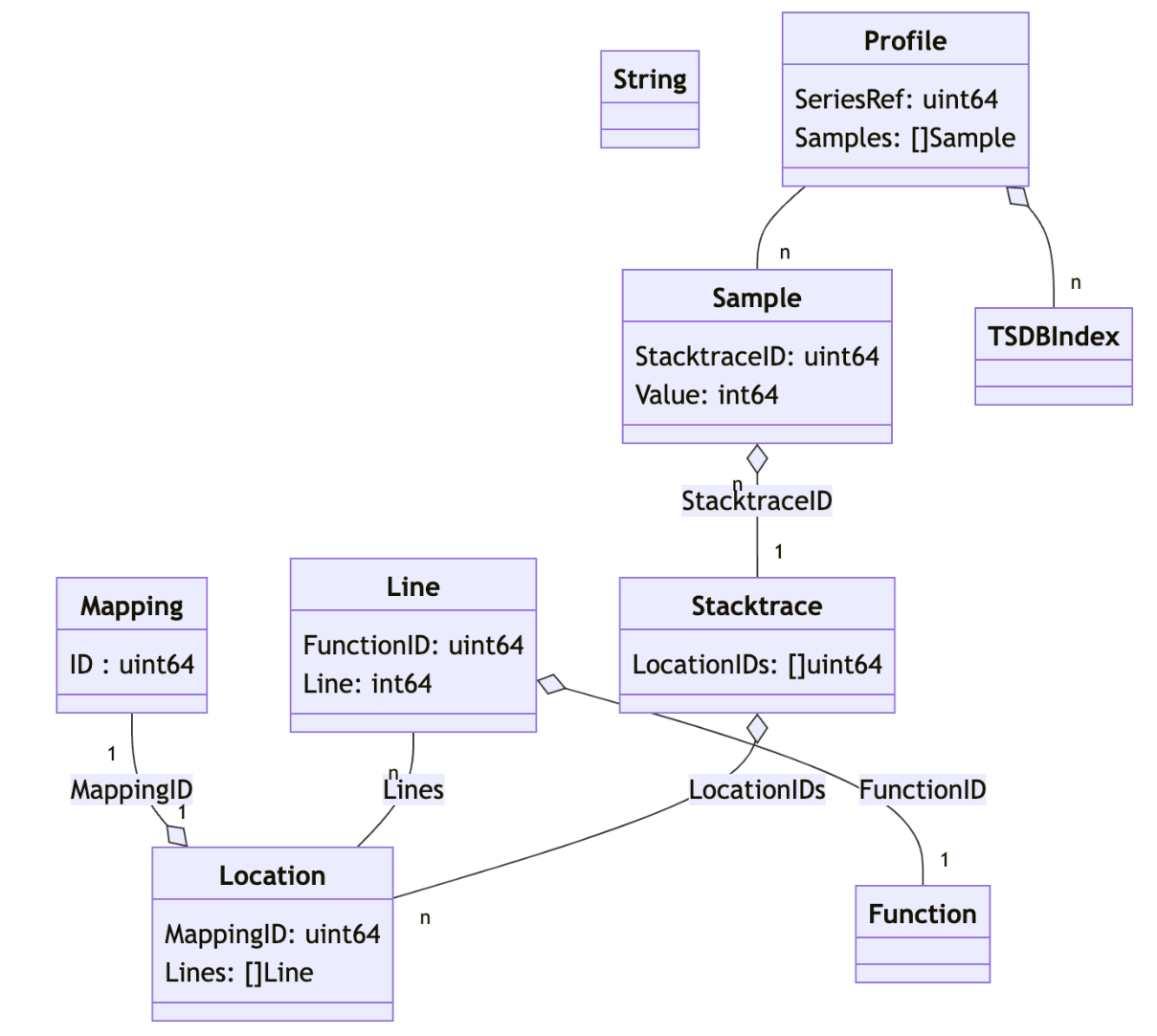
基本对齐 pprof 模型的列存数据表,来自 Phlare
pprof 在设计上是跨语言的,它理应成为一个跨语言标准,但受限于历史的进程,大多数语言的采集工具比它的历史更久,各种工具和采集链已经较为成熟,所以,除了 Go 语言有着极好的 pprof 支持,其他语言都没有成熟的 pprof 格式转换方案(例如 Python 虽然有,但缺乏维护)。这中间的沟壑既给了 Pyroscope 较多的对接工作量,也给 OT 的标准化留足了空间。
Open Telemetry 预期将 Profiling 格式做一个标准化,包括了非常多的工作内容:
- 尽可能多兼容各种 Profiling 格式
- 应尽可能高效地传输分析数据,并且制定一个无损的 Profiling 模型,重点在于解析、转码(与其他格式之间的转换)和分析的效率上
- 应该可以清晰地映射到标准数据模型(例如 collapsed、pprof、JFR 等)
- 应该包含表示其他 OT Signal 之间关系的机制(例如 span 中的调用链)
- 对于已经流行的 Profiler,保持尽可能小的转换开销
OT 的愿景是非常美好的,但从可观察的进展来说,并不是非常顺利,至少距离上一次有效的更新已经过了几个月了。所以,现阶段在没有 OT 标准化格式之前,pprof 仍旧是 Profiling 数据格式为数不多的选择。
总结
Continuous Profiling 是一个不新不旧的领域,有着不大不小的市场,伴随着可观测领域常见的问题。在 OT 标准化前,Pyroscope 算是领先了一个身位,但各产品仍处于百舸争流的阶段,需要 Continuous Focusing 。