什么是 Traces ?
这两年可观测领域受到了比较多的关注,其中以 Traces 尤为突出。那么什么是 Traces 呢?它又能做什么呢?我们来看看官方给予的定义:
Traces give us the big picture of what happens when a request is made to an application
简单来说:Traces 能 描绘 一个请求在应用中究竟做了什么。
描绘?
对于原始的 Traces 数据而言,与其说是“描绘”,不如说是“描述”:应用做的事情被拆解成一个个小的单元(Span),多个有着父子关系的 Span 组成一个完整的 Trace。尽管它的数据详尽——包括属性(attributes)、事件(Events)、上下文(Context)等内容,但是最大问题也很明显:不够直观,有效信息获取效率低。
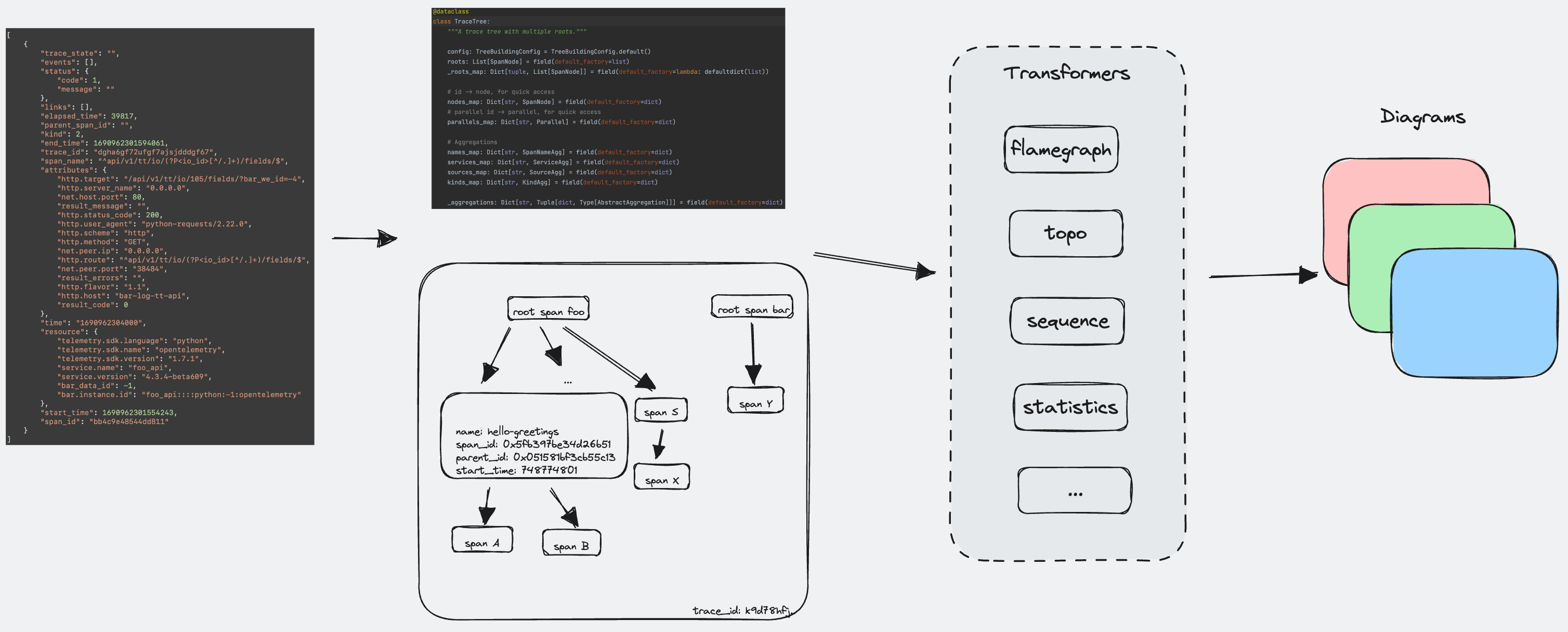
1 | { |
所以更多维、更直观的图表就显得尤为必要了。
各种变换形态
首先,我们需要将 Traces 数据抽象成一棵多叉树。
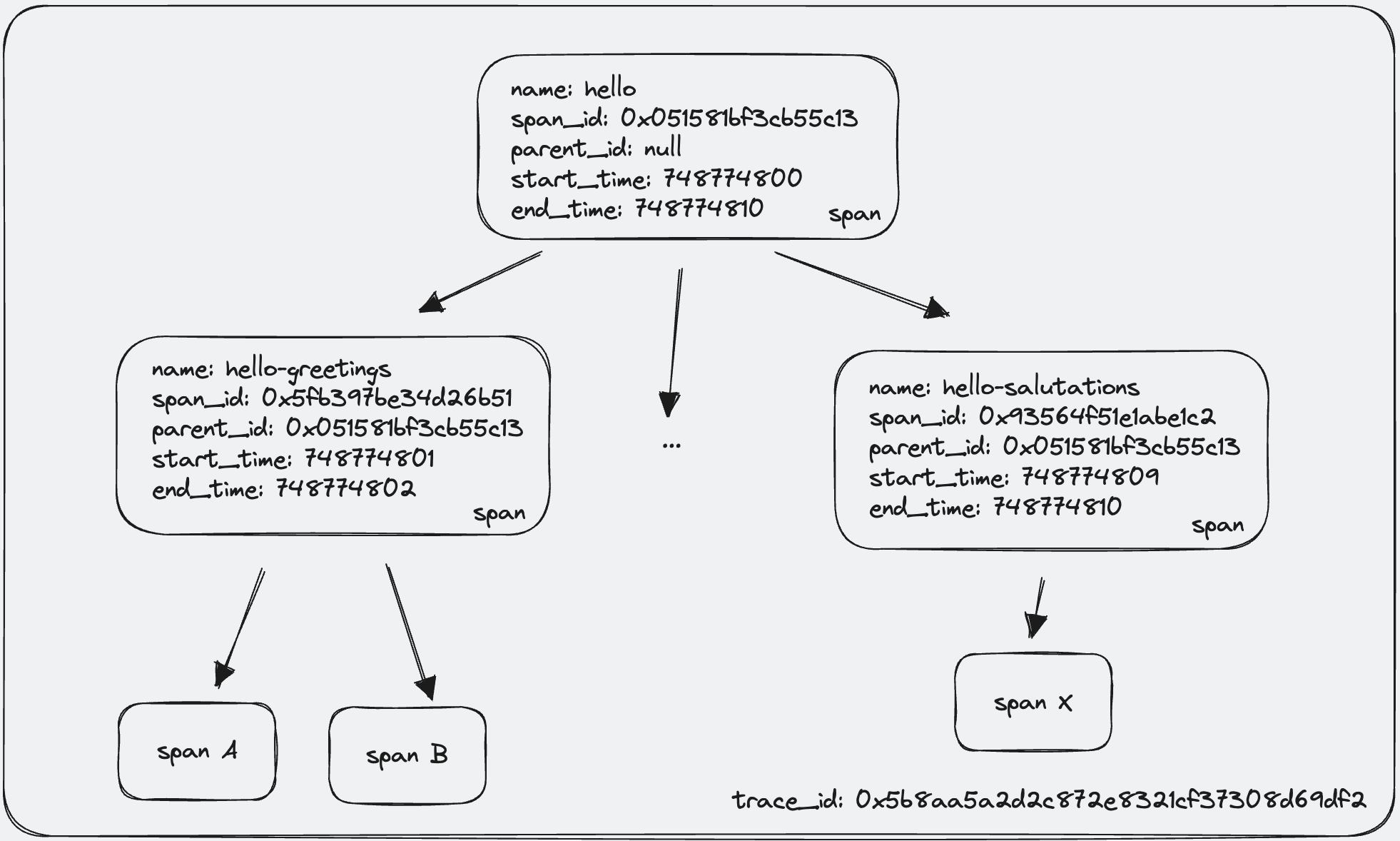
一个简单的 Trace 多叉树
在这棵多叉树的各个节点信息中,藏着 Trace 的多个维度信息:
- Span 之间的调用关系:
parent_id指向调用它的父级节点 - Span 调用的时序关系:
start_time&end_time表明了 Span 的开始结束时间点 - Span 耗时:
elapsed_time代表该 Span 的耗时
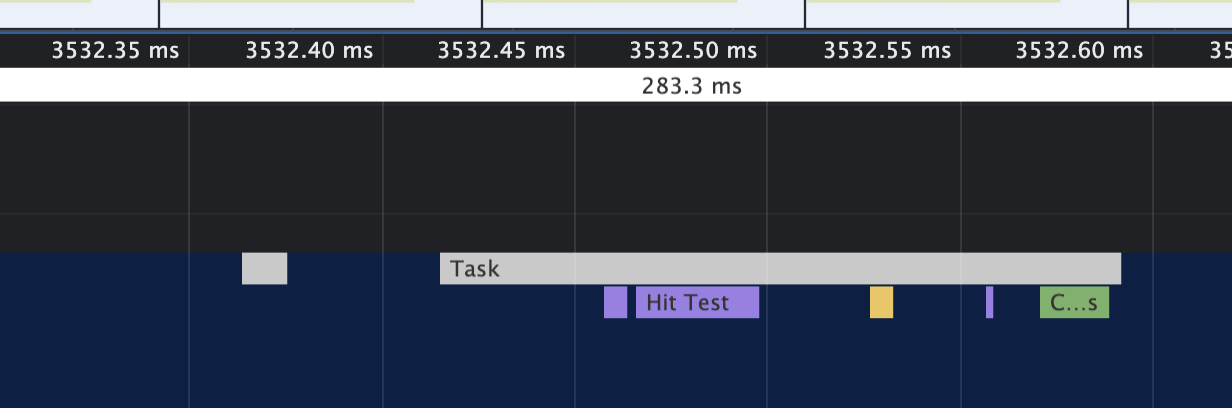
Timeline 时间线图
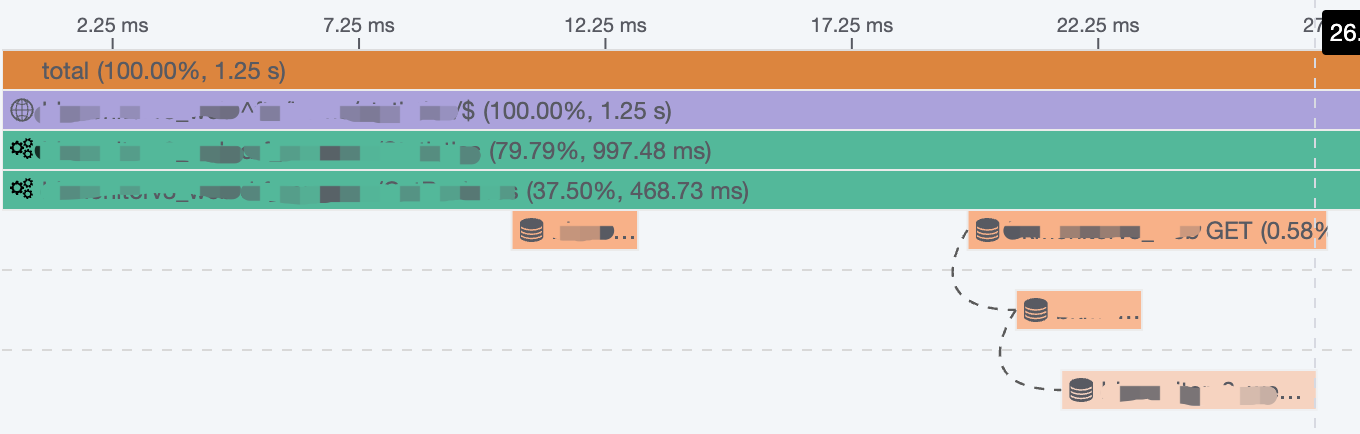
首先,我们通过「Timeline 图」(a.k.a 瀑布图)纵览所有 Span 之间的父子关系、时序、耗时。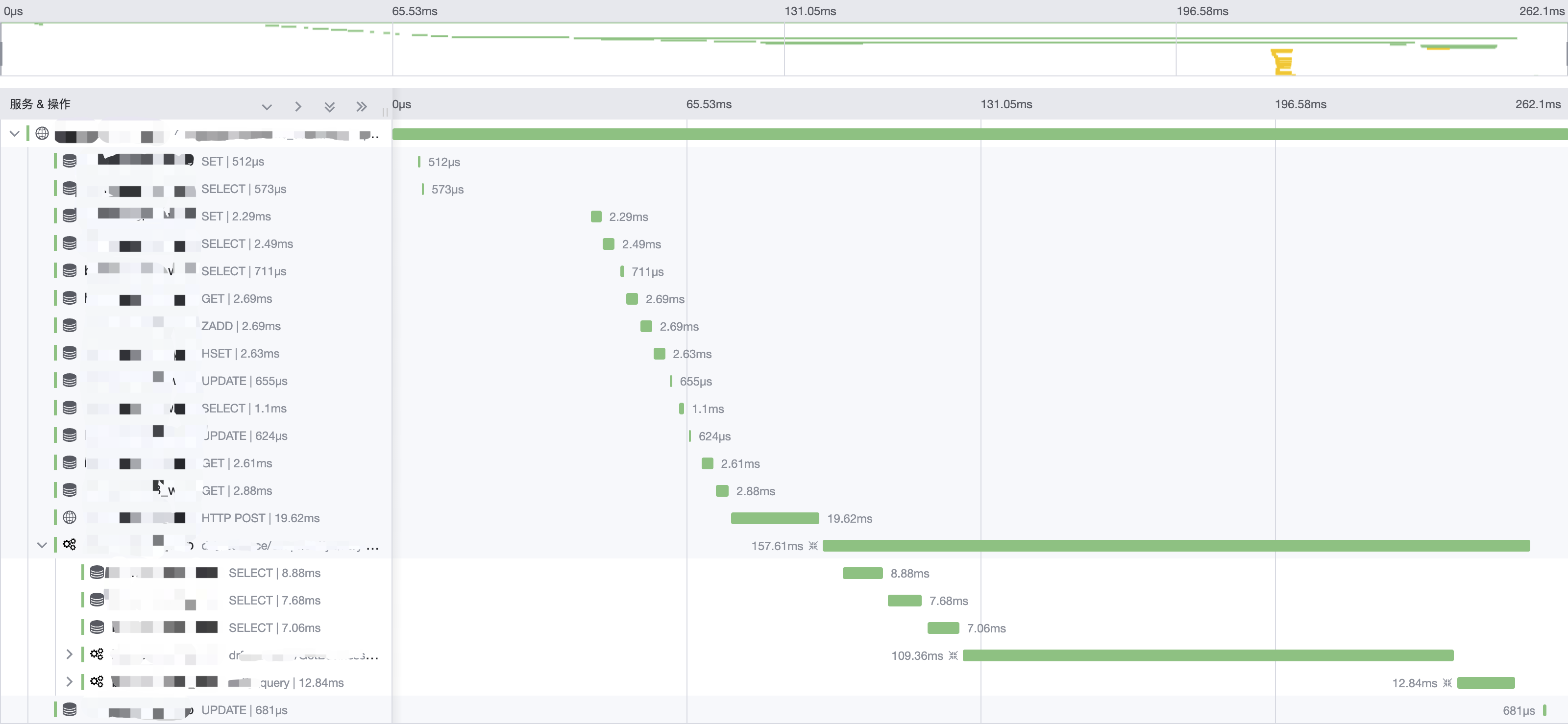
在时间线图中,你可以掌握单个 Trace 的全部信息:
- 查看所有的 Span 概况,按照服务进行颜色区分,同时展示所有的父子关系。
- 通过时间轴和线条的长度判断出 Span 具体耗时。
- 点击 Span 可以查看其详细信息,包括标签和进程等所有上报信息。
虽然它全能,但在一些具体维度上仍旧不够直观,所以我们要在这棵多叉树上进行精加工:
- Span 之间的父子关系 → 拓扑图
- 以接口、服务等维度汇聚统计信息 → 表格统计
- Span 调用的时序 → 时序图
- Span 耗时分布 → 火焰图
下面就来分享一下相关图表的展示逻辑细节。
拓扑图
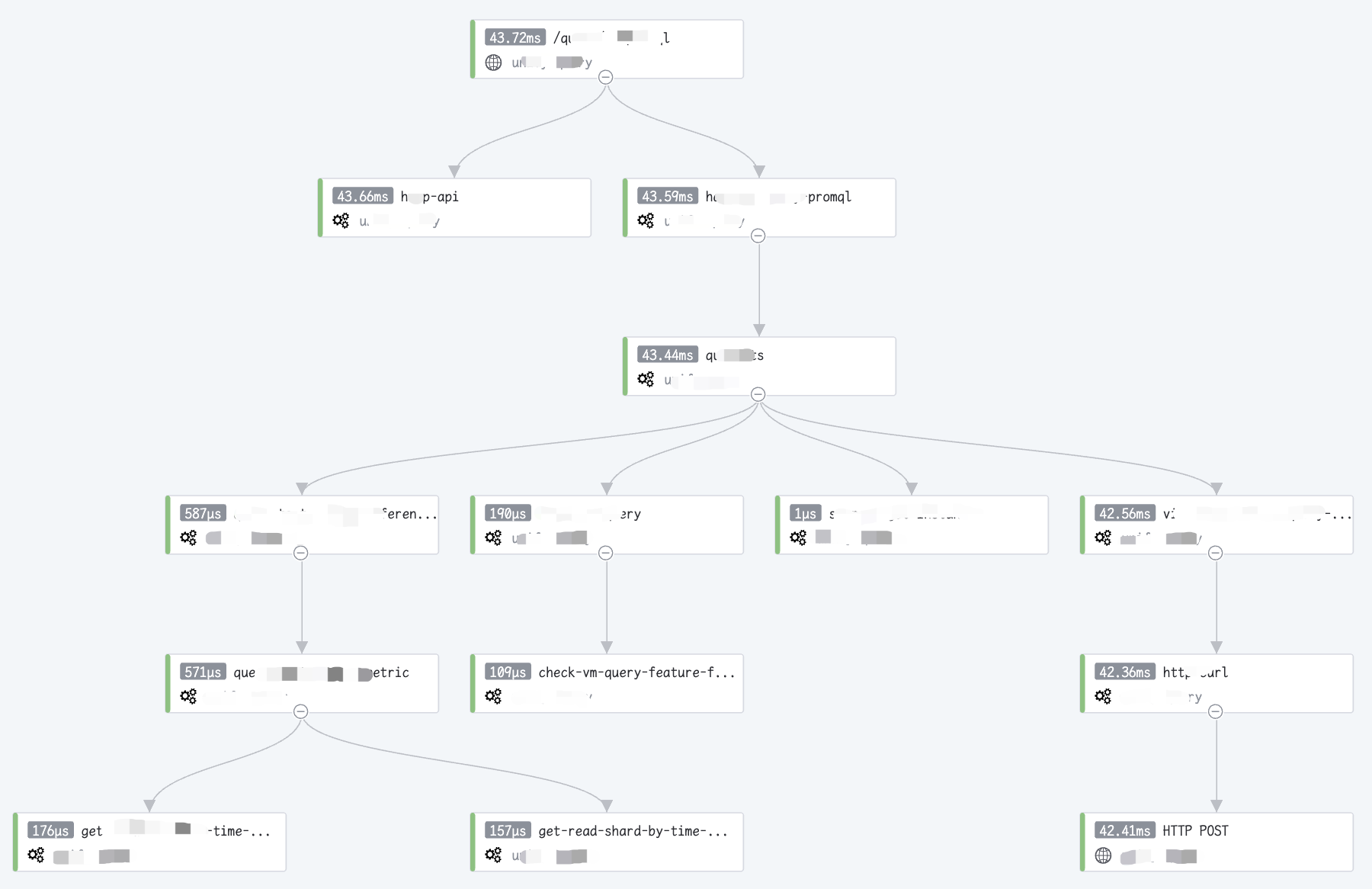
对于拓扑图而言,它将主要的重点放在了 Span 之间的关系上,你可以很清晰地获取到 Trace 的调用关系、层级等信息,但同时它也刻意忽略了时序信息,下面会有较多场景会提到这一点。
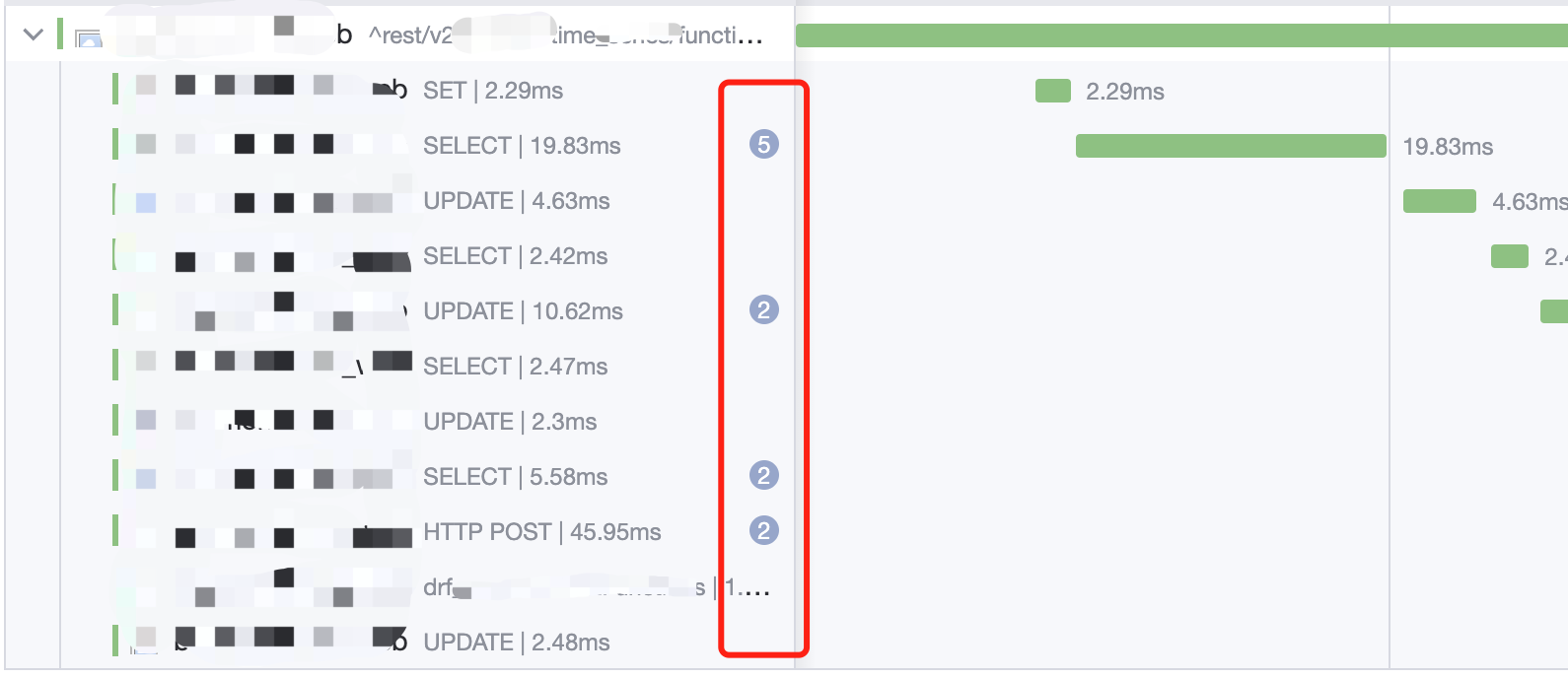
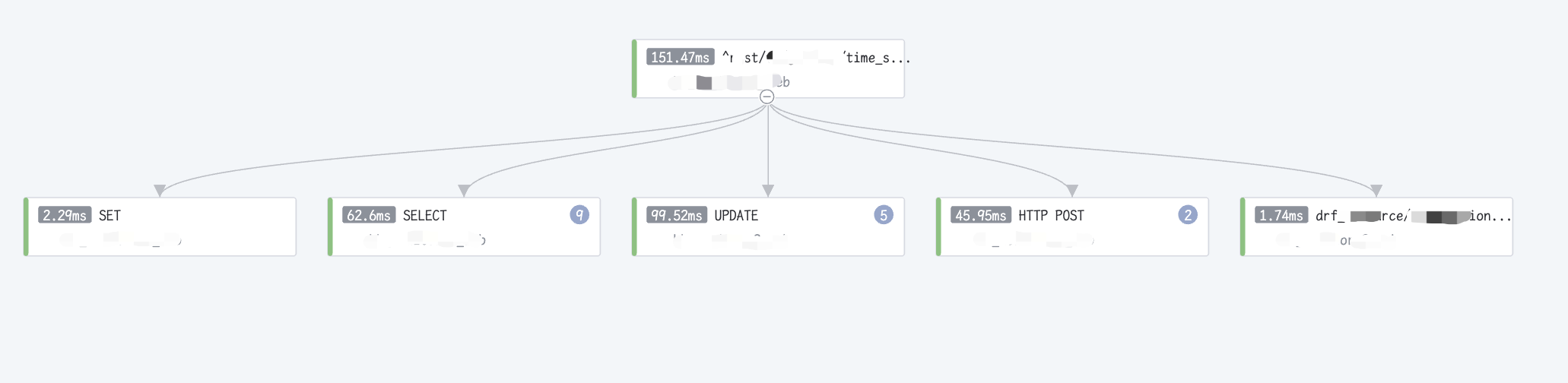
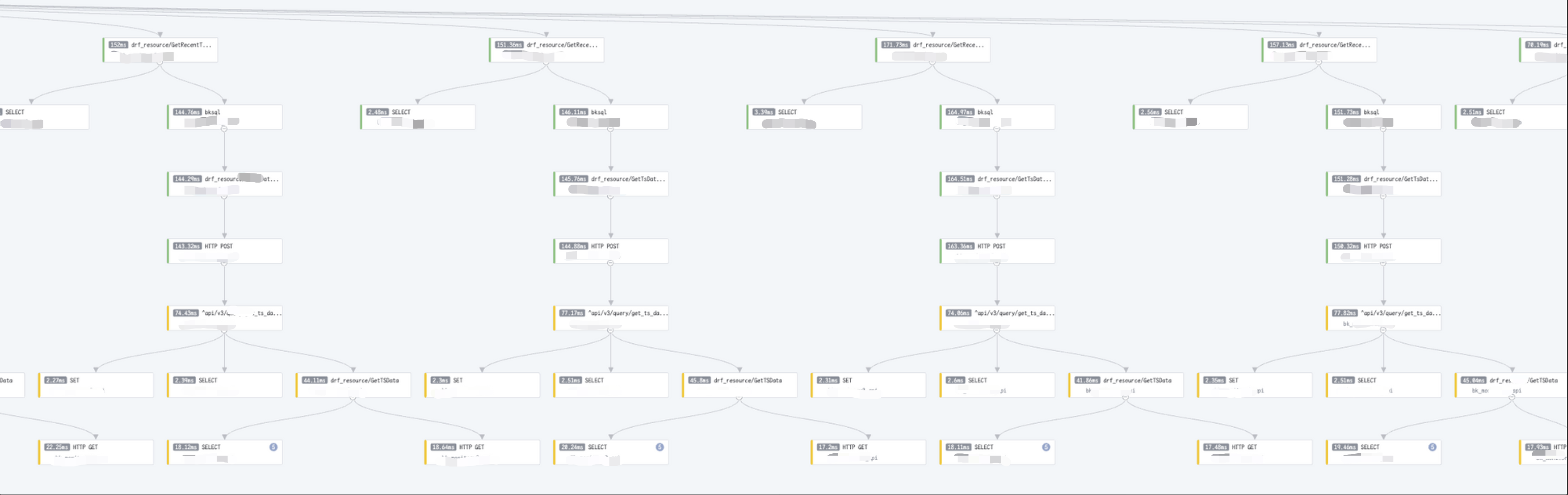
表格统计
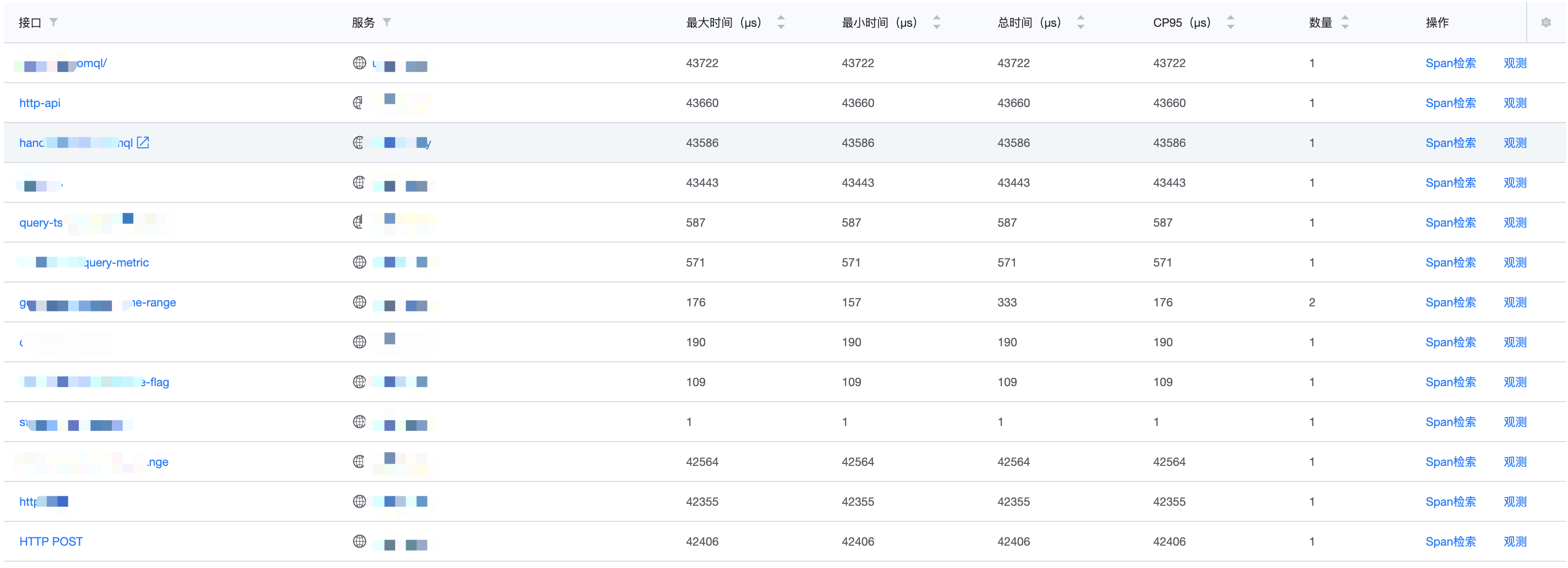
表格统计的重点是,将 Trace 中的汇聚信息平铺展示出来。这里有两个需要额外解释的概念:接口&服务。
接口和服务
【接口】的内容实际上就是 span_name —— 操作名称的别名。而【服务】则是来自于 resource.service_name ,表明该 Span 所属的服务,以简单的名字字符串作为 Trace 维度的唯一标识。
时序图
时序图,顾名思义,主要是想突出 Trace 的时序特性。
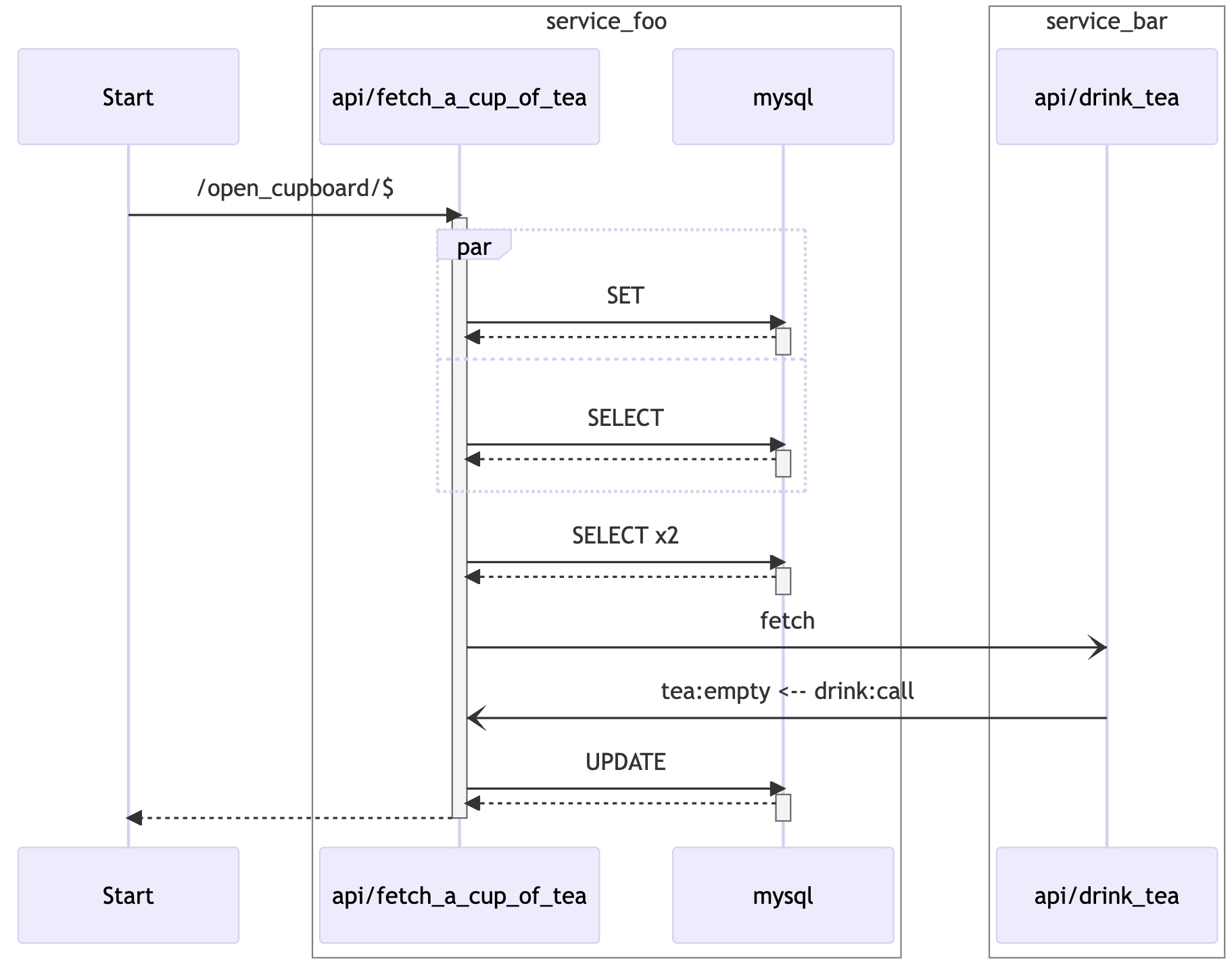
时序图示意图
这是一种 UML 行为图,我们将它原本的几种元素结合 Trace 场景做了一个概念转换:
- 物件(Object)和生命线(Lifeline)用一个 方框+垂直线条 来共同表示 接口或服务在 Trace 流程中的生命周期。
- 讯息(Message)用一条 水平带箭头的连线 表示 接口或服务之间的调用,也就是 Span 的主要体现形式。
- 活化(Activation):用一个 垂直方向的矩形 表示 接口或服务的耗时区间,它并不精确,但能表达出不同 Span 的耗时前后时序关系。
此外,时序图有一些额外封装和添加的概念,下面我们会一一展开解释。
服务接口聚合
首先是对服务聚合的概念阐释,和时间线图类似,我们会从 resource.service_name 字段中抽取所有 Span 共有的服务概念。额外地,我们从 attributes 字段中的信息尝试判断当前 Span 的形态,将不同的场景做一个简单区分。如图所示, service_foo 服务中会区分出 api/* 和 mysql 两种接口,它可以让你更好地了解不同组件之间的调用关系。

相对时序
与时间线图不同的是,时序图为了表达服务与服务之间的调用关系,默认采用了“相对时序”,而非严格按照 start_time 排序的“绝对时序”。
- 绝对时序:所有线条都按照 span 的绝对发生时间绘制,淡化父子关系
- 相对时序:父子的关系优先于绝对时间,同一个父节点下的 span 有绝对的先后顺序,不同父节点下的 span 不保证其绘制的先后顺序
我们举一个更容易理解的例子:假设某一个 Trace 有5个 Span,s1 → s5。s2 是 s3 的父节点,s4 是 s5 的父节点。先按照“绝对时序”画出时序图:
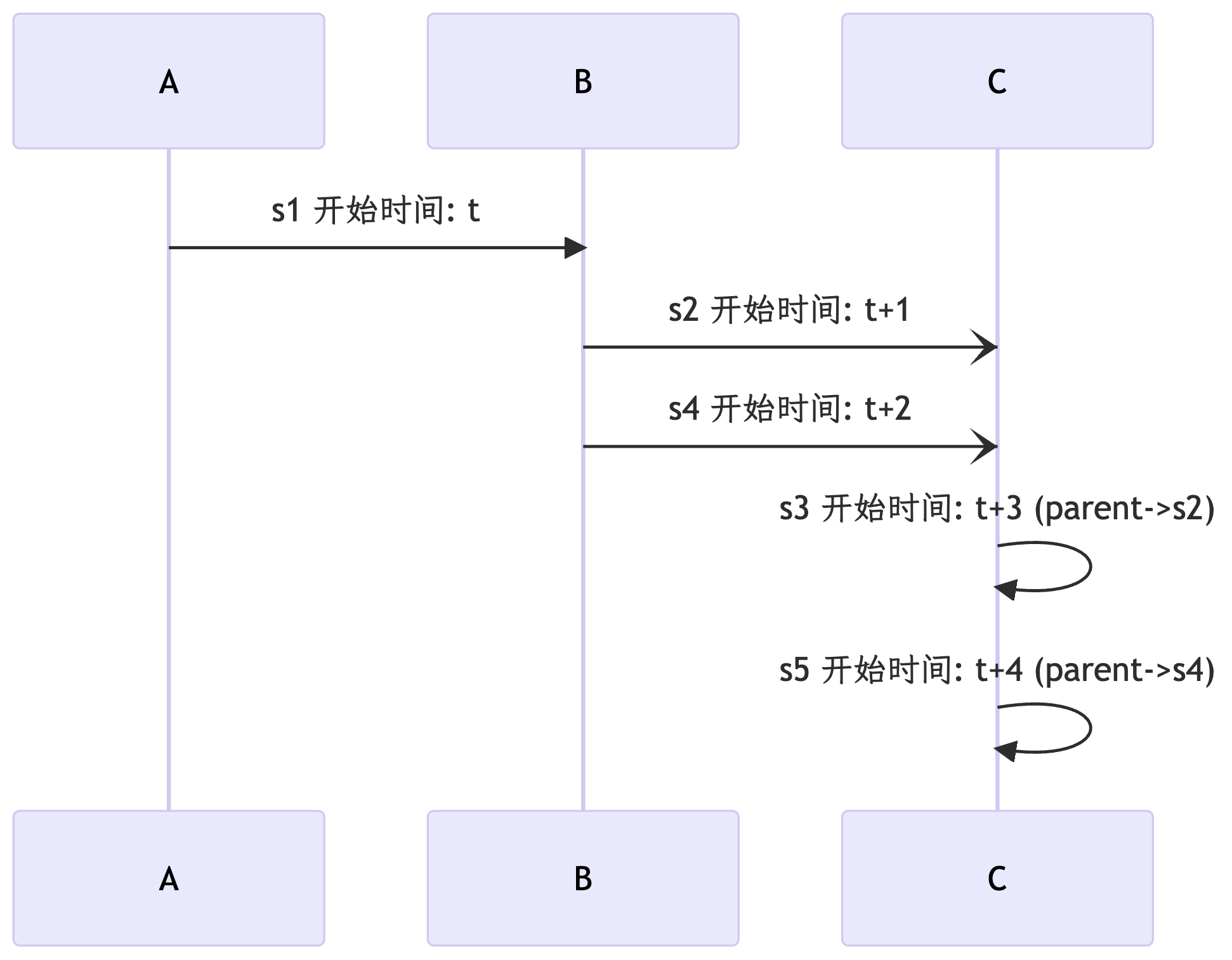
虽然它严格遵循了“时序”,但是原本的父子关系被淡化了,仅从图中基本没法判断出 s2 & s3 \ s4 & s5 之间有什么联系(图中的 t 是为了展示额外添加的,真实数据中不存在)。
我们再按照“相对时序”来绘制: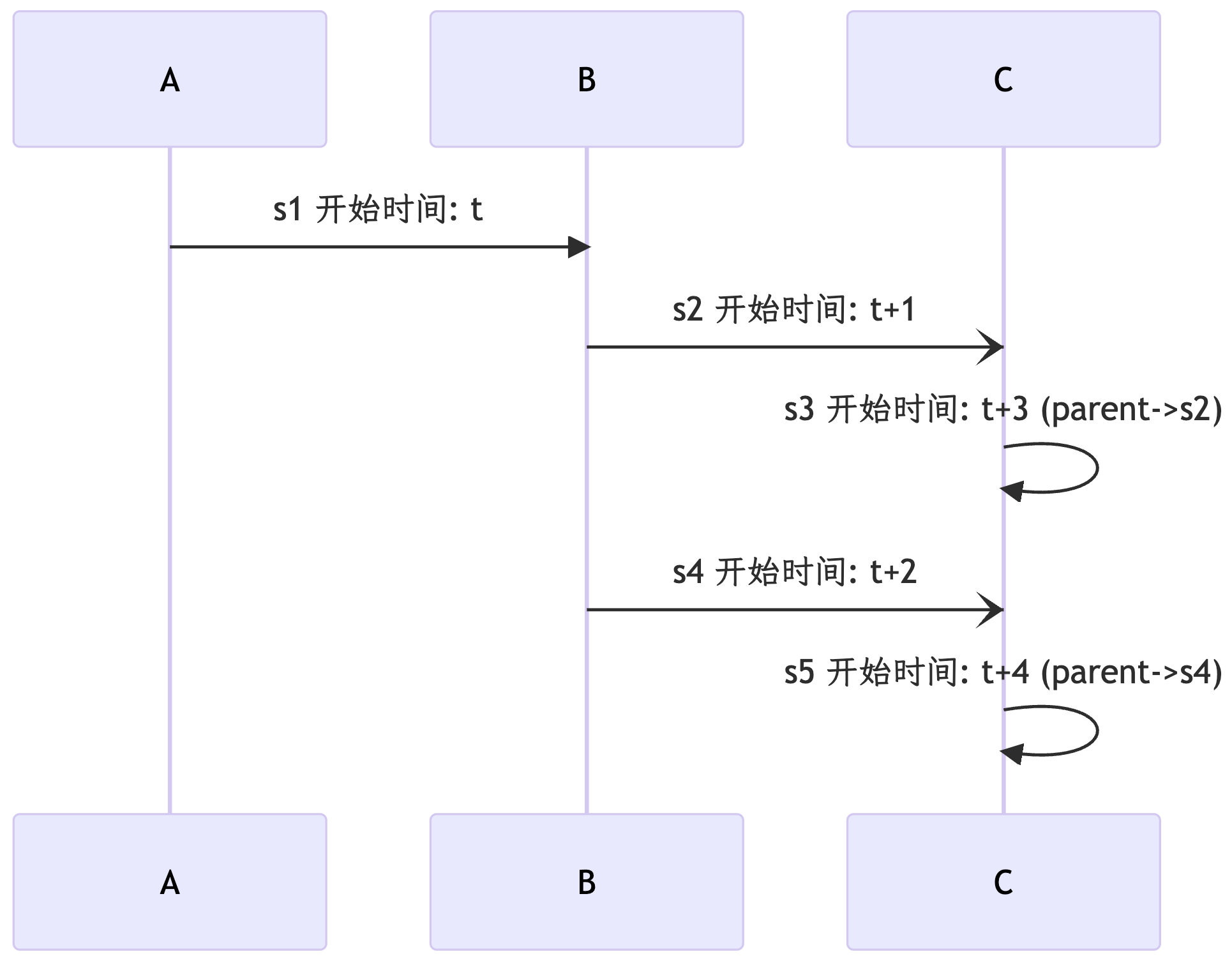
可以看到,虽然我们稍微“牺牲”了一些时序上的绝对性,但是调用之间的关系更清晰了,用户更容易在庞大的图表中找到调用关系。
虚拟的开始节点
在图中有两个内容是“虚拟”出来的:开始节点和返回虚线。
**当时序上的第一个 Span(通常是根 Span)的类型是被调或异步被调时,**为了表示该特性我们会在图的最左侧补充上一个虚拟的 Start ,它没有其他实际意义,只是表达整个追踪的“开始”节点。

调用返回
第二个添加的虚拟内容就是返回虚线。
为了更加准确地表达 Span 在时序上的流入流出状态,我们会根据 Span 中的 end_time 生成的一个虚拟调用返回,同时开启一个时序图的 Activation ,用来做 Span 耗时的示意。需要注意的是:它并不是在所有的请求中都会开启,当且仅当 Span 的调用类型是主调。
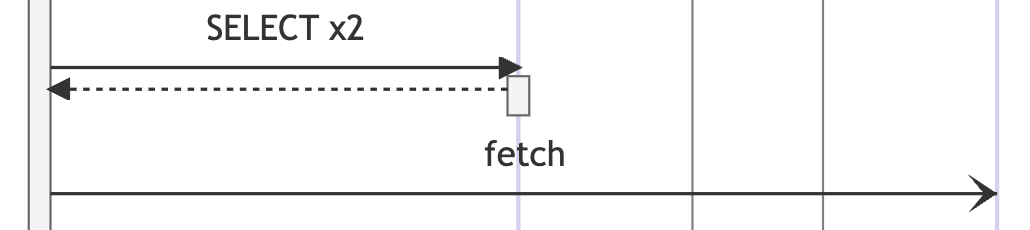
当 Span 是异步类型时,我们会使用特殊箭头 → ,且不会增加虚拟返回
主调被调合并
当父 Span 是主调,子 Span 是被调时,我们会把两个 Span 的信息合并到同一个 Message 中。

合并后
火焰图
火焰图最早是用在 CPU 性能分析领域,最大的特点是形似火焰,CPU 耗时越大在图中展示的元素越宽,开发者可以通过寻找“平顶山”来确定性能瓶颈。
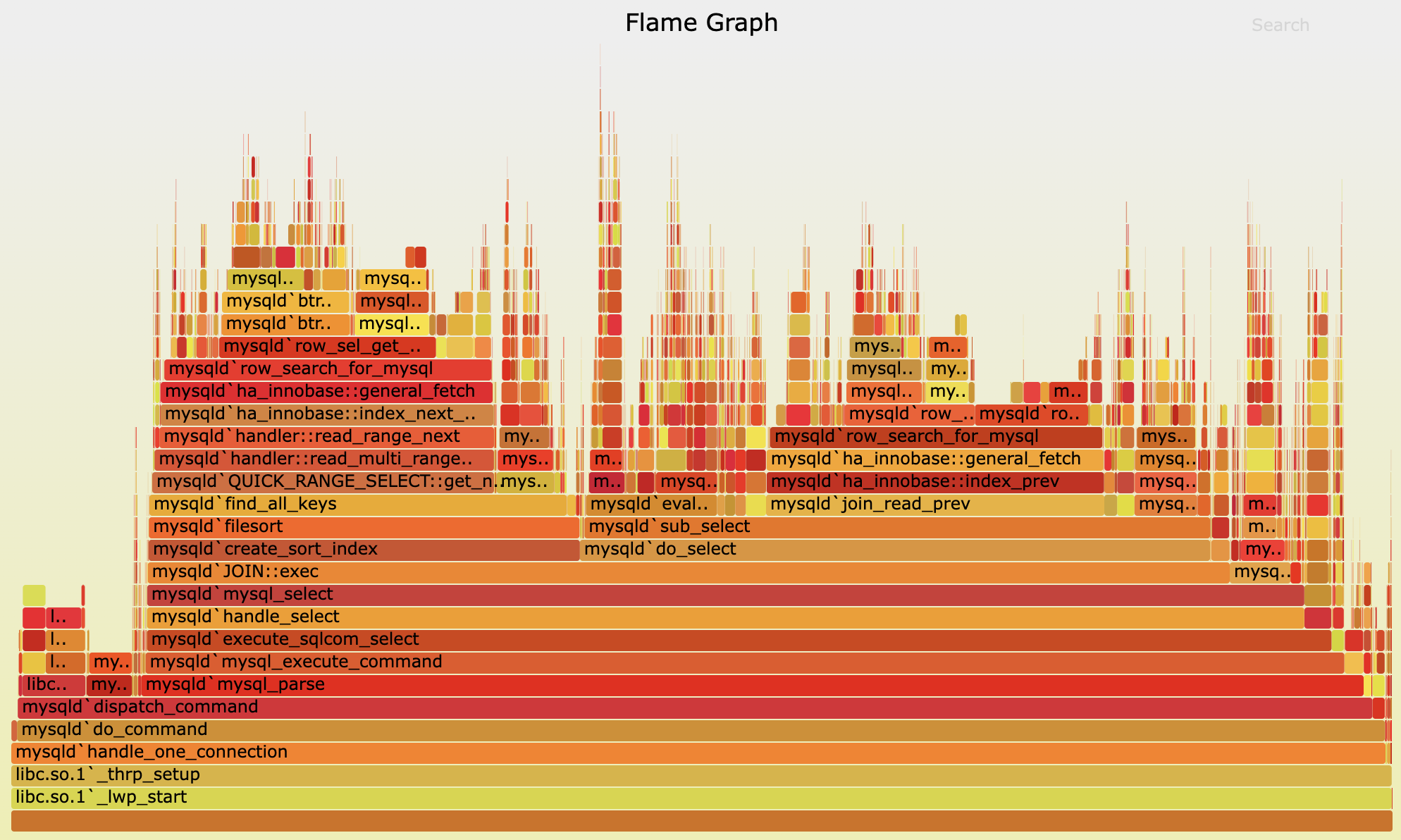
原始火焰图,X轴按照字母序排列
原始的局限
火焰图最大的局限在于无法精准地展示 Trace 中的 Span “并行”的概念,即使已经有无数“前者”在尝试了。

观测云的做法,看起来貌似可行
当复杂场景发生时,必须要舍弃一些信息的精准性
原始火焰图更多用在 Profiling 场景下,此时对于程序函数调用栈关系的可视度有着更高的要求——即对于 Y 轴信息的准确程度。但是对于 Trace 而言,Span 的执行时间长度、顺序在展示上的优先级更高。所以,在 Trace 领域我们采用了一种火焰图的变体—— FlameChart。它最早来自 Google Chrome 的 Web Inspector:
最大的区别是它的 X 轴变成了时间轴,它会准确的表达 Span 的开始和结束时间,而 Y 轴的栈调用信息从绝对值变成相对值。但它一开始的场景更多是在 single-threaded 的 JavaScript 分析,也不能妥善地处理好“多线程”的状况。
经过一番搜索,受到一个 Python Profiling 可视化工具的启发:
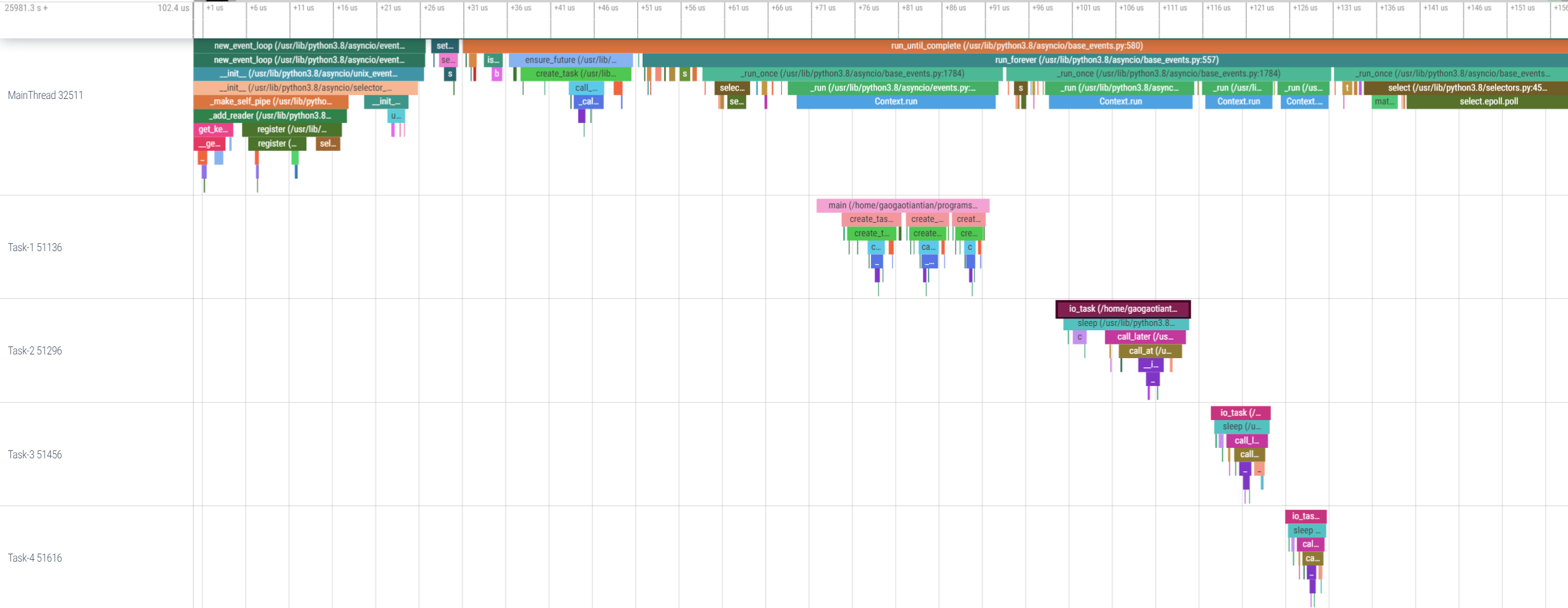
类似地,我们在变体 FlameChart 上做了进一步的变形,增加了 thread line ——一个用水平虚线单独格出来的行——额外展示“并行”信息。

在图中我们可以看到相较于最原始的火焰图有两个明显的变化:
- X 轴增加了时间纬度,按照 Span 的开始时间&结束时间,保证长短比例,严格分布在 X 轴上
- Y 轴在相对情况下保持调用的父子关系,但不绝对表示栈的调用深度。
X 轴相对容易理解,Y轴的变化稍微展开阐述。这里有一个关键的概念——“并行”,当火焰图中有“并行”元素存在时,会单独在原来的火焰图下方另起一“虚线行”展示这个“并行”信息。
没有并行,和普通 flamechart 无异:

当存在并行内容时,将会有一条**“连接线”将所有 Span 的头部都连接到一起,表示他们的“并行”性,此时 Y 轴仅在同一 thread line中保持相对的调用深度,不同thread line之间的调用深度需要通过“连接线”**来辅助判断。
细节优化
折叠
由于是多叉树,节点宽度过大往往是控制展示的痛点。在很多场景下,同一次请求中存在大量的重复调用,它们代表的意义近似、耗时量级相同,却占据了画幅中的大量面积,所以我们针对这个场景进行了展示优化:将相似的兄弟节点进行分组折叠。判断节点是否相似取决于以下几个因素:
- Span Name 是否相同?
- Service Name 是否相同?
- 是否在时序上相邻?
- 是否存在错误?
不同的展示图表有不同的特性,选取的判断策略也有所不同:
瀑布图、时序图重点展示了时序,所以必须相邻才能被折叠到一起。
拓扑图淡化了时序信息,所以即使时序不接壤,也会被折叠到一起。
同时,由于拓扑图的折叠只会保留一棵抽象的树,当存在两棵子树完全相同时也会被折叠到一起。
四棵一模一样的树

聚合到一起,原本子树中已有的分组也会被同时累加聚合
并行/并发推测
兄弟 Span 之间很多时候会存在并行或者并发的情况,因为没有直接的字段指示,所以我们在多叉树的处理过程中增加了一个“并行/并发推测”的步骤。当存在以下任意两种场景时,我们会认为这些 Span 之间存在“并行或并发”的情况:
- 兄弟 Span 之间的执行时间存在重叠,侧重于同一时间段内同时运行,即并「行」。
- 兄弟 Span 的开始时间极为接近(当前默认探测时长为
500μs),侧重于近乎在同一个时间点发起,即并「发」。
这里我们可以回顾上文提到的时序图,里面就包含了一个并发的展示样例:
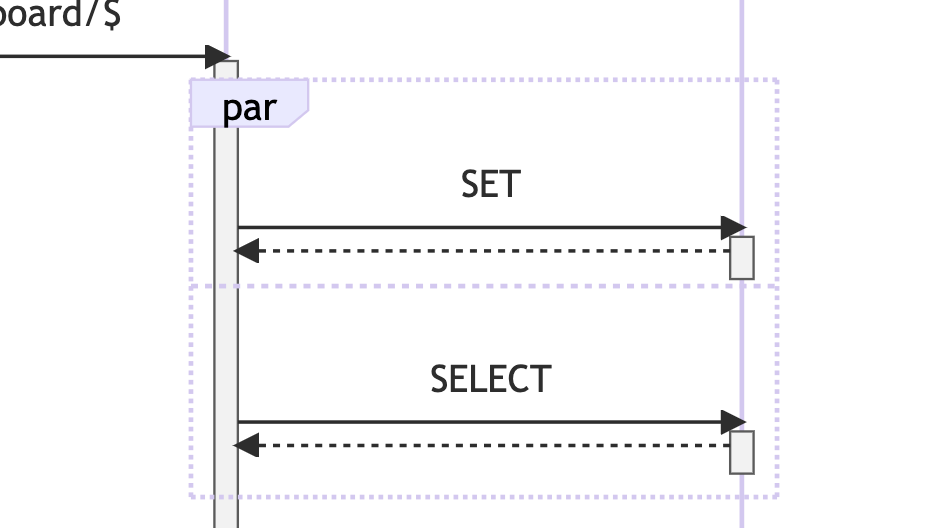
需要注意的是,这里我们提到的“并行”,是一个逻辑概念,是我们根据数据状态进行的一种“推测”,而非坚定的”判断“,被”推测“为并行的元素间可能不存在”真实“的物理并发行为,而同样存在一些“真实”的物理并发没有被并行”推测”所标记。
对比
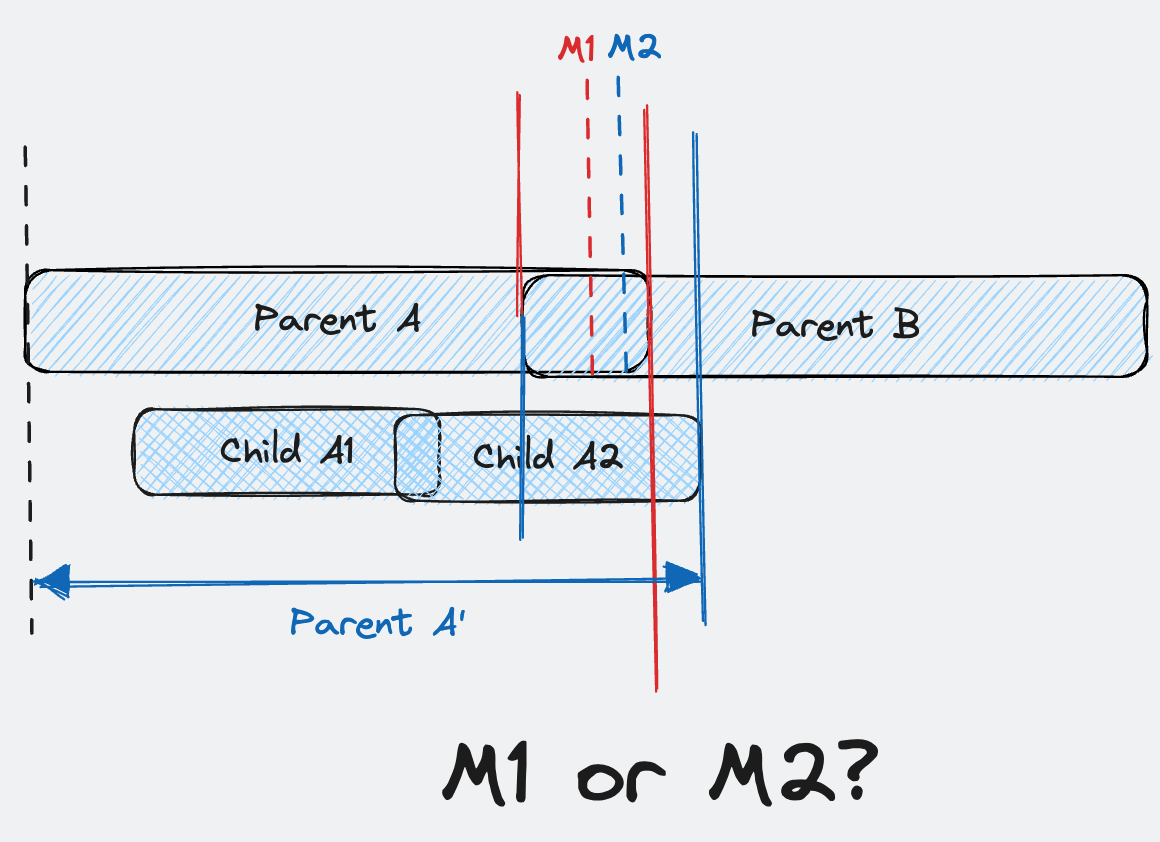
我们常常需要对比不同时间段内**相似的 Trace,它可以帮助我们在更长的时间维度上对程序行为进行观测。**正如上文提到每一个 Trace 都是一颗多叉树,相似 Trace 的对比其实就是多叉树对比的策略,但和普通多叉树不同的是,兄弟节点之间是时序相关的。
对比策略
在 Trace 场景中我们采用了通过相对时序的方案对两棵多叉树进行对比。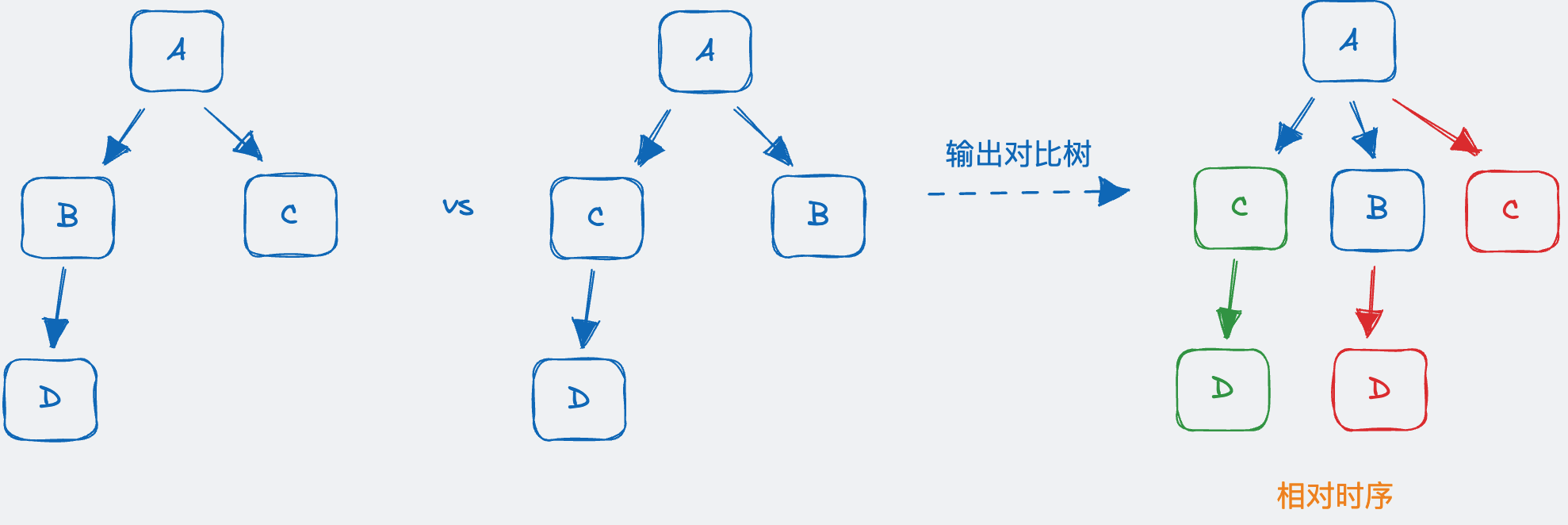
相对时序的意思是,我们会根据节点所在兄弟之间的位置来确定其是否在对比树中存在。对于 baseline 的某个节点而言,查找可能会产生四种结果:
UNCHANGED,未发生变化,相对位置、Span 关键信息、耗时均未发生改变CHANGED,发生变化,相对位置、Span 关键信息已找到,但是耗时有了增减REMOVED,在 baseline 树中不存在,但是存在于对比树,认为是对比树新增的节点ADDED,未在对比树中找到对应 Span,判断该节点已经被删除
可比性评估
有时候两棵 Trace 树的差异非常大,进行对比展示的意义不大,我们采取了一种 吻合度按层级递减 的策略对两棵树的可比性进行了一个评估。采取这个思路的原因是:越靠近根的节点对于树的相似性有更多的影响。
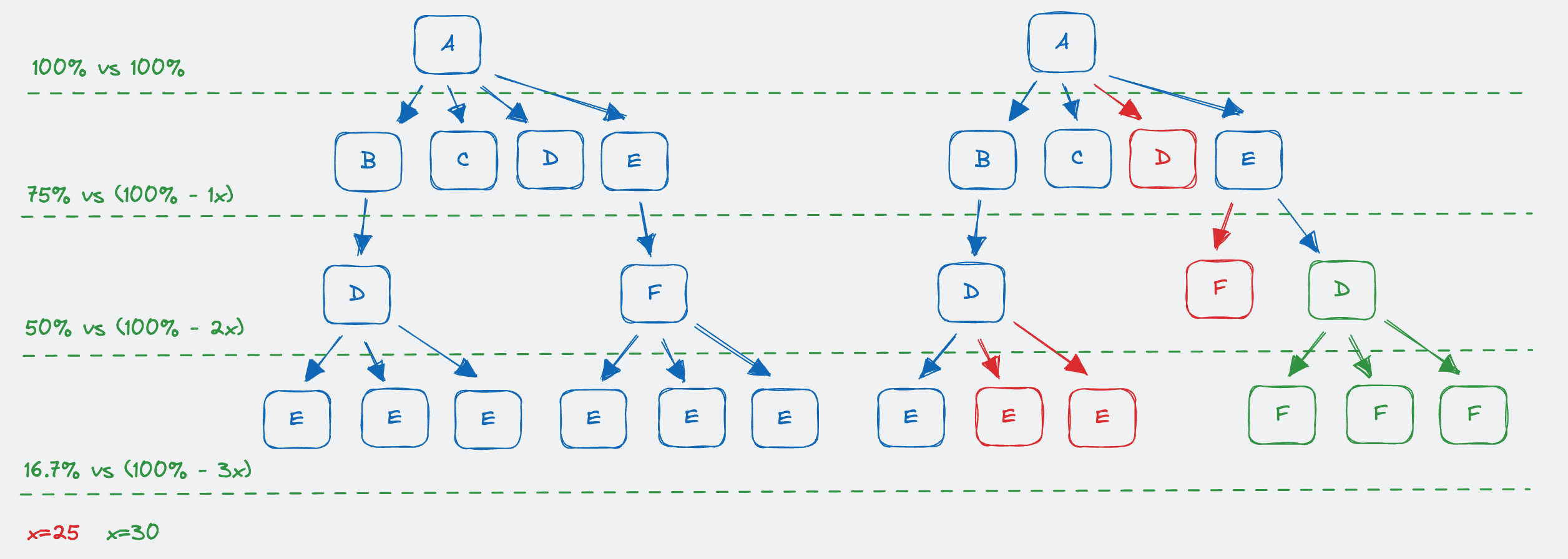
在这里我们按照层级,从上到下进行评估可比性。当任意层级评估不可比,即判定两棵树不可比。
依照刚才提到的整体思路,越是靠近根节点的层级,应该有更高的相似性:从左侧 baseline 树的角度出发,计算出节点在对比树中存在的比例是否满足该层级的最低吻合度
我们定义了一个变量:吻合度层级递减比例 X ,对于层级而言,最低吻合度就是 (100 - level * X) 。这里的 X 的取值会决定两棵树是否可比,如图所示:
- 当
X=25时,level=3层级的吻合度1/6=16.7%是小于100 - 3*25=25%,所以判定这两棵树是不可比的。 - 当
X=30时,level=3层级的吻合度1/6=16.7%是大于100 - 3*30=10%,所以判定这两棵树是可比的。
(对于具体 X 的调控,我们暂时采用了一个静态值,更灵活的调整策略还在根据实际场景进行摸索。)
忽略小差异
当然存在一些非常小的 Trace 树不太适用吻合度递减的评估策略。
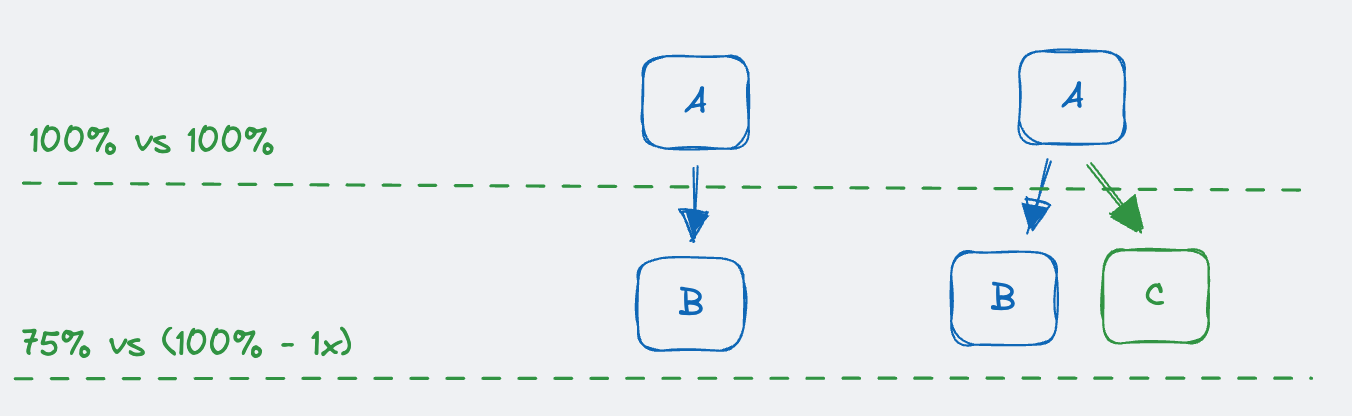
足够小的树,需要 X 值较大才能保证对比性
我们设定了一个阈值 Y,当层级节点数小于 Y 时我们不予进行对比评估。
Fin
基于当前的生产管线,后续可以对更多可视化图表,让天下没有难懂的 Trace 😎
(以上内容均已开源 👾)