起因
我们在日常使用 ELK 链路的时候,经常会碰到一个问题,由于链路涉及的组件较多,一旦当其中某些组件出现问题,就会出现“事件风暴”,如果没有做好相关的告警或者资源管控,很可能会使链路发生崩溃。
在官方文档中,我们可以看到一个相关的描述: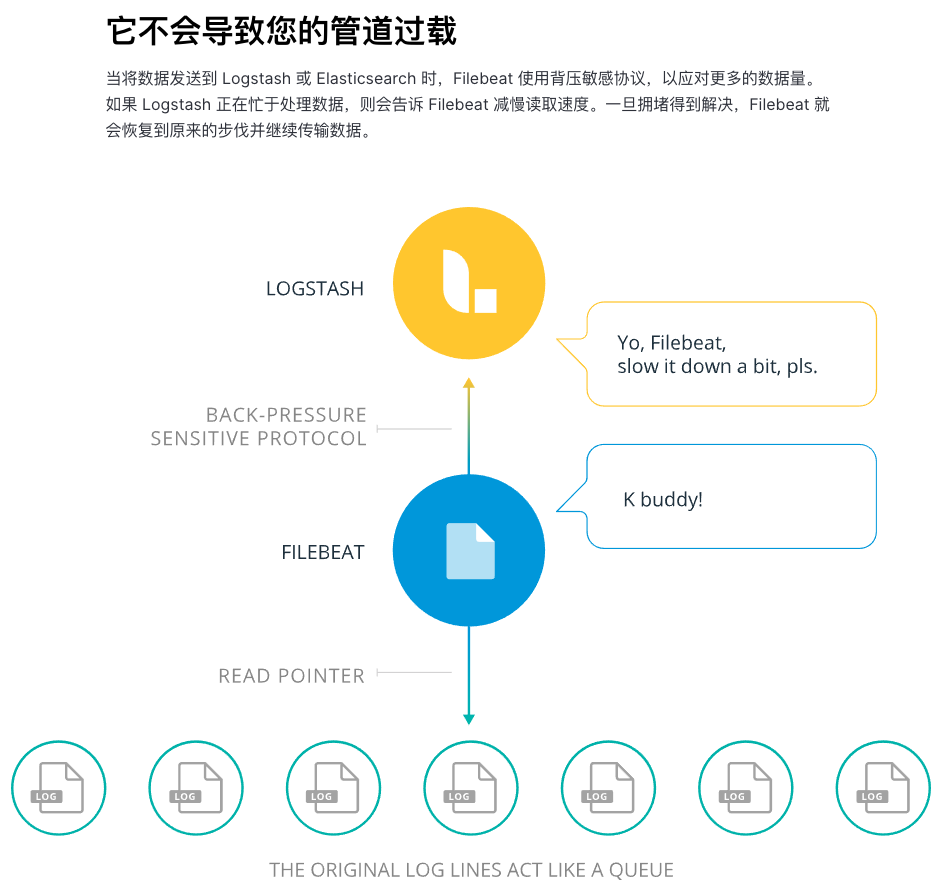
然而,在我们实践过程中并没有图中描绘得如此理想,很多情况下,在后端 ES 写入出现问题时,前端输入(如 filebeat)并不会减慢采集速率,导致中间的缓存队列(Redis)存储爆满,在没有做好资源隔离时,引发其他问题。
所以我们就来仔细研究一下 ELK 背压原理,看看如何才能调试出一条伸缩自如、百折不挠的 ELK 链路。
什么时候触发背压
Logstash 内部会有一个 buffer 区域缓存一定量的事件,这个队列可以存储在内存或磁盘。一旦当这个队列缓存跑满,Logstash 会反向给事件输入端(Input)施加 “back pressure”(不返回 ACK),限制流量流入。
1 | # 缓存落盘 |
类似我们给这个队列配置 8gb 的缓存,当事件队列里全都是 unACKed 事件,并且缓存达到了 8gb,Logstash 就不再接受任何事件推送,直到将队列内的事件被消费重新恢复。
对于 Input 端而言,官方提供的组件也都实现了类似逻辑,例如 Filebeat,当没有收到 output ACK 事件数量积累到 最大限制(默认 4096) 时,会停止读取文件,直到组件内部缓存队列能够被消费,所以理论上,只要能够通过 TCP 互相连接的组件,ELK 提供的组件应该都是可以实现背压能力的。
ELK 直接传输 vs 外部消息队列
经典的 ELK 链路中,我们通常为了会扩展 buffer,在 Beats 和 Logstash 之间增加一个中间队列(例如 Kafka、Redis),相比较直接使用 ELK 链路传输,在背压问题上又有哪些优劣呢?
首先是是否都能触发背压?
在上文中提到的,我们使用 Redis 是无法正常触发背压的,理论上说不通。于是经过一番搜索,发现filebeat 需要使用 >=6.4的版本,而我们正好用的是 6.3😂 ⇒ 问题传送门,从问题的描述上来看,只要升级到了 6.4 背压问题就能解决,但没有调查就没有发言权,索性做一个简单的背压测试。
0. 准备测试环境
准备一个装好 Helm 的 Kubernetes 集群,然后依次安装所需组件:
1 | # 建议拷贝 values.yaml 作为 values,方便修改 |
通过 values 配置将三者串联起来,Logstash 可以先配置 output.stdout 直接打印,快速确认链路通常。
准备一个可以不断触发日志的 pod
1 | kind: Pod |
1. 外部消息队列
外部消息队列组件较多,一般来说瓶颈可能会出在最后的 ElastcSearch 上,这种情况下,前端的 filebeat 是无法感知的,只要外部消息队列一直可用,filebeat 是不会触发背压。所以我们主要测试 当外部消息队列也不可用 的情况。
正常采集,filebeat 采集日志:
1 | 2020-12-17T08:15:51.663Z INFO [monitoring] log/log.go:144 |
关闭 Redis ,立即观察:
1 | 2020-12-17T08:17:44.272Z ERROR [redis] redis/client.go:239 Failed to RPUSH to redis list with: EOF |
此时,采集并没有停止,队列事件数量上升了,但还没有塞满。
静待一段时间再观察:
1 | "pipeline":{"clients":1,"events":{"active":4117,"retry":1}}} |
可以到看到,unACKed的数量超过了默认的 4096,数量停在了 4117 上(为什么是 4117?),没有新的事件推送了,可以认为背压已经生效。(但是要注意,此时文件句柄并不会释放,需要 通过 clost_timeout 来保证机器文件系统健康)
再次打开 Redis
1 | # redis 重新连上 |
unACKed 的事件迅速被消费,背压消失, filebeat 采集恢复正常。
2. 直接传输
通过配置,我们将 Redis 挪到 Logstash 后端,再把 filebeat 日志直接怼到 Logstash。需要测试的是,当最后端的 output (例如 ES,我们这里偷懒用了 Redis)挂掉,观察Logstash → FIlebeat 整体的背压情况。
当链路通畅,采集正常后,我们尝试关掉 Redis,然后立即观测 Logstash 日志
1 | [2020-12-17T10:03:30,095][WARN ][logstash.outputs.redis ][main][22ee6501492f55ca3f6485661fbbafb6131941aad2d5c08d163a871e724cfb81] Failed to send event to Redis {:event=>#<LogStash::Event:0x1a2ed42b>, :identity=>(中间省略一万字) `block in start_workers'"]} |
这时候我们会发现,Filebeat 的事件队列已经开始堆积了(这里如此敏感,是因为我们 Logstash 只设置了内存队列,空间有限,如果使用了较大的磁盘存储,可能需要积攒非常久),类似 Redis 方案,当队列堆积到 4117 时就不再有新事件采集了。
重新打开 Redis 就绪后,数秒内 Filebeat 迅速恢复采集,整条链路的感知还是比较灵敏的。
如何观测背压事件?
一般来说,背压产生的原因通常是链路中有组件发生了异常(例如 ES 状态变红),导致数据流断裂,这是需要维护者介入的重要事件,所以如何能够被及时准确地观测到,是衡量方案的重要指标。
由于我们的使用场景里,ElasticSearch 是托管给其他团队维护的,暂时没有异常告警,所以只能在链路监控上做文章。
外部消息队列
以 Redis 为例,我们可以比较轻松地监控其队列长度、所消耗的资源量来判断其状态,是比较容易观测的。
直接传输
在一番简单 Google 之后,发现了悲剧的事实——翻遍了 ES 的论坛和 Github issue,没有找到明确的背压事件标志:
- 2016 年有人因为 CPU 吃满而发生背压,发现很难观测
- 同年,在 Github 中也有人创建了 相关 issue ,然而到现在也无人回应
- 2018年,Logstash 如何检测背压事件的问题 也无人回应
加上官方文档的语焉不详,看来并没有显式的日志可以轻松地 直接监测 到。
但对直接传输方案的偏爱(少一个组件,少点维护成本),经过进一步研究,采用了一个间接观测方法 —— 将 Logstash 的 metrics 转换成 Prometheus 格式(借助 logstash_exporter),再根据事件发送和接收的速率判断。

当一切正常
当后端发生异常,out_total 增速会立即小于 in_total
可以比较清晰的看到,Events 的接收和发送都处在一个比较相近的速率,如果在 filter 不出错的情况下,事件发送的速率大大小于事件的接收,就基本说明了后端存在问题,背压应该很快就要被触发了。

背压发生,不再有新的事件推送进来
当背压触发, logstash_node_pipeline_events_in_total 和 logstash_node_pipeline_events_out_total 二者的增速都降为了 0。
所以,解决方法就非常简单了,在 Prometheus 配置类似告警语句即可:
1 | # 近十分钟 Logstash 无输入 |
再配置上简单的图表,就能清晰的看到 Logstash 的采集速率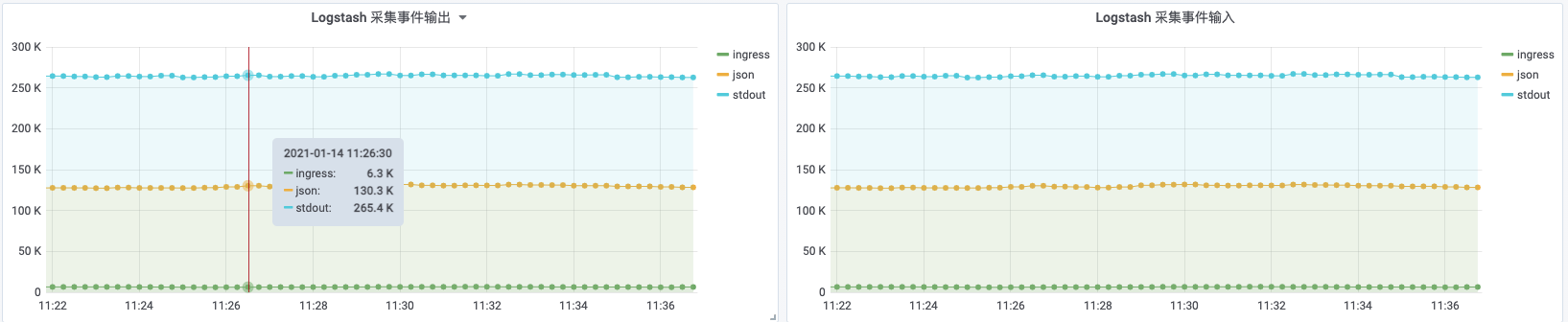
结论
总结一下上面提到的两种方案,在背压问题上的优劣:
- 外部消息队列在观测上更优,有比较多的方案可以更直观地判断链路健康状态
- 当背压发生,外部消息队列会将更多内容采集到链路中,而不是暂时让他们呆在硬盘,如果故障处理的速度较慢,那么链路的数据可靠性就非常重要了,一旦链路数据丢失(例如 Redis 未能及时落地,内存事件丢失),日志会有更多丢失
- 直接传输方案在组件维护、问题排查上更容易
- 外部消息队列方案要更关注组件版本,对旧系统不那么友好
具体选择那种方式采集日志,需要根据实际情况抉择。
参考:
- https://discuss.elastic.co/t/where-do-incoming-events-go-when-logstash-is-cpu-bound/65197
- https://www.elastic.co/guide/en/logstash/current/persistent-queues.html
- https://discuss.elastic.co/t/redis-input-plugin-back-pressure-issue/150826
- https://github.com/elastic/beats/issues/7743
- https://discuss.elastic.co/t/filebeat-harvester-open-file-count-increasing-when-logstash-output-to-elasticsearch-fails/249892