引
这里有一段看起来稀松平常、人畜无害的 Python 代码,你可以试着执行一下:
1 | import re |
不知道大家执行了多久,在我开发机上使用 Python 3.6+(包括 3.10.x)需要耗费20秒以上,即使 CPU ——Apple M1 Pro 的性能已经相当强悍了。
可以试想一下,如果在生产环境服务的关键请求链路中存在这样正则匹配,加上不可控的用户输入,很容易落入“性能陷阱”,轻则拖慢系统,重则直接让服务暴露在 ReDoS (Regual Expression Denial-of-Service) 的风险之下。
随手一搜,已经有不少相关的案例发生:CVE-2021-23343 、CVE-2021-41817。所以,它值得我们格外重视。
Evil Regex 大敌当前
先来看一些和上面例子类似的、典型的邪恶正则:
(a+)+([a-zA-Z]+)*(a|aa)+(a|a?)+(a|a)+$(.*a){x} for x \> 10
它们都有共同的一些特点:
- 存在子表达重复——形如
()+、()* - 在重复的子表达中:
- 存在重复项——
(a+)+ - 存在交替重复——
(a|aa)+
- 存在重复项——
- 在重复的子表达的末尾,存在一个子表达式无法匹配的内容,例如
(a|a)+$
那么为什么这些重复会导致匹配速度如此之慢呢?我们要看看正则的具体实现思路。
知己知彼,百战不殆
当前主流语言的正则实现机制都是构建**非确定有限状态自动机(NFA)** ,相较于确定有限状态自动机(DFA),前者会使用回溯法(backtracking),这也是导致邪恶正则存在的根因。
NFA vs DFA
(该章节中的图例均来自这篇文章,我在这里做了内容简化,建议有兴趣的同学阅读英文原文)
FA 有限自动机,又称 FSM 有限状态机,在当前的语境下,我们统一都是用 FA 来描述。这种计算模型比较常见,所以我们就着重关注 NFA 和 DFA 的对比。
首先,来看一个简单的正则表达式—— a(bb)+a ,它可以转换成以下两种表达:

DFA

NFA
上面两张图能够很清晰地表现出二者的不同:
- DFA 中,每一个状态在接收到输入时,下一个状态都是确定的。
- NFA 中,存在某些状态在接收到输入时,无法确定下一个状态:例如图中的 S2 接收到字符 b,S1 和 S3 都是可能的下一个状态。所以系统在分支选择时,需要进行猜测。
理论上,每一条正则表达式都可以等同转换成一个 NFA 状态机,那么如果使用 NFA 进行匹配,如何处理猜测分支就很重要了。下面我们来看一个简单遍历猜测的例子。
根据正则 abab|abbb 我们可以建立如下的 NFA:
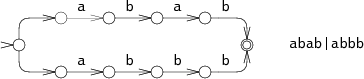
模拟计算机匹配输入 abbb,可以有如下两种路径:
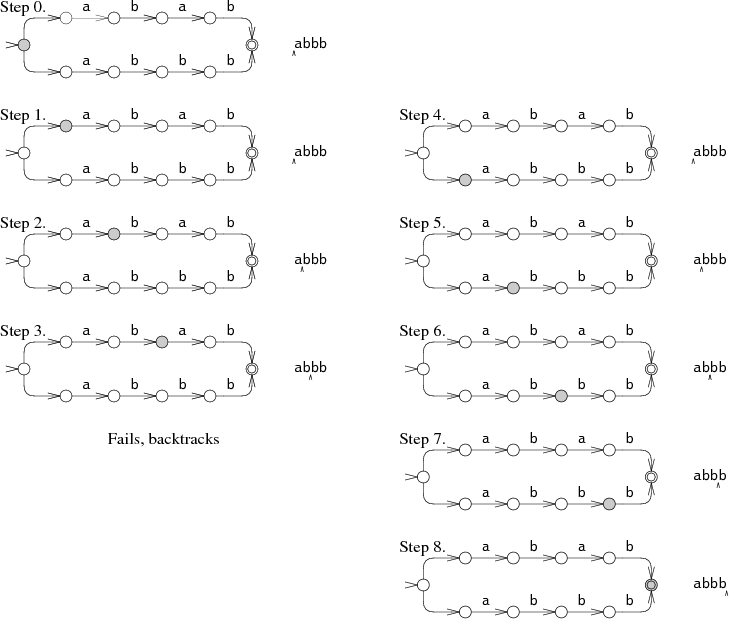
以 Step 0 开始的路径,在匹配到第三个字符时出错,此时不得不采用回溯,再次从一开始进行匹配,即 Step 4 → Step 8。
通过这个回溯方法,我们来思考正则表达式 $a?^{n}a^{n}$ 与字符串 $a^{n}$ 匹配:
如果每一次判断 $a$ 是否存在时,都会尝试匹配“存在”的情况,再匹配不存在的情况,而整个字符串长度为 $n$,也就是时间复杂度为 $O(2^{n})$。
当前主流的语言(Perl, PCRE, Python, Ruby等)采用了递归来实现深度优先回溯,相较于 Thompson NFA,最终实现的效果都是惊人的糟糕。
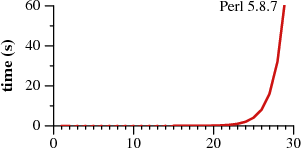
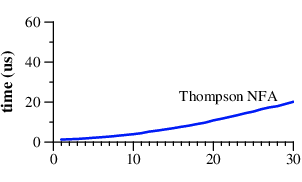
Thompson NFA 构造 vs DFA
为什么使用了 Thompson NFA 构造出的正则匹配会快这么多呢?主要的原因是:通过划分多个子表达式,合并相同的内容,从而减少了回溯次数。
$(ε|a*b)$ 可以转换成 Thompson 构造,图示:
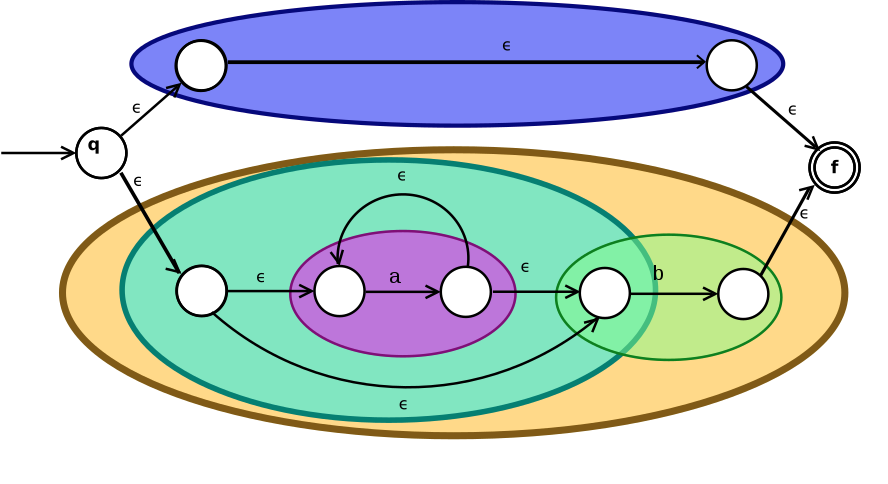
稍微做一些解释:
- q 是开始,f 是结束,白圈是状态,连线是流转
- ε 代表着无输入
通过以上的结构,Thompson NFA 匹配的时间复杂度为 $O(n)$,空间复杂度为$O(n^{2})$。
而 DFA 更容易理解,因为它是典型的空间换时间。
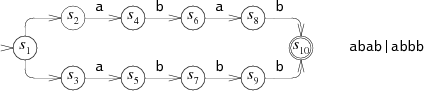
NFA
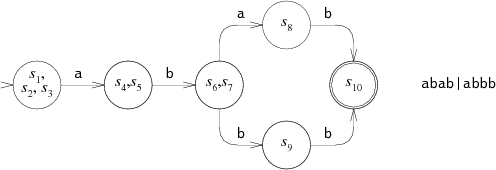
DFA
可以看到每一个 DFA 的状态都等同于某一时刻 NFA 状态列表,所以 DFA 在最坏情况下,空间复杂度 $O(2^{n})$,也会在构建阶段消耗更多时间。同时没有了回溯,整个匹配时间就是字符串长度,复杂度为 $O(n)$。为了保证 DFA 的空间消耗,一般都会额外对构建出的 DFA 做简化,减少图的大小。
为什么主流编程语言这么慢?
说来有趣,Thompson NFA 构造法应该是编译原理的基础概念,DFA 方法从概念上也是比较简单,为什么当前的主流语言没有采用,反而采用了一个带有回溯的、效果远逊的版本?
经过一番冲浪搜索,简单概括我找到的结论:历史的局限。
While writing the text editor sam [6] in the early 1980s, Rob Pike wrote a new regular expression implementation, which Dave Presotto extracted into a library that appeared in the Eighth Edition. Pike’s implementation incorporated submatch tracking into an efficient NFA simulation but, like the rest of the Eighth Edition source, was not widely distributed. Pike himself did not realize that his technique was anything new. Henry Spencer reimplemented the Eighth Edition library interface from scratch, but using backtracking, and released his implementation into the public domain. It became very widely used, eventually serving as the basis for the slow regular expression implementations mentioned earlier: Perl, PCRE, Python, and so on.
可以从上文得知,正则匹配的实现首先需要兼容原来的使用方式,而当时开发者并未了解 NFA 模拟方法,而是自己从零实现了一个回溯方法,并且被广泛地传播开了。即使这个实现很慢,但是由于已经被大规模采用,且能满足大多数的使用场景,各个主流语言也没有替换它。
正面对抗 Evil Regex
既然当前主流语言的实现肯定会存在性能陷阱,我们是否有办法检测邪恶正则呢?答案是肯定的。
在社区里有不少相关项目,例如:regexploit 、redos-detector 、vuln-regex-detector 等,它们都可以扫描出有风险的正则,就像这样:
1 | $ echo "(a+)+s" | regexploit |
但是它们局限于静态的正则扫描,对于我们开发者而言,静态防御并不能完全清除风险。更好的思路是直接替换语言的默认实现。以 Python 举例,我们也找到了一些替换库:
pyre2
1 | pip install pyre2 |
来自 Google re2 模块的 Python 封装 pyre2,使用了 DFA 的构造方式。可以替换原生 re 模块,大多数场景都可以得到速度的稳步提升,不存在性能陷阱。
但对于 DFA 模拟来说,都是自古华山一条道,比如 (?P=<name>) 这样的属于 backreference 的捕获组语法就无法支持了。
regex
1 | pip install regex |
regex 模块并未使用 DFA 构造,在完全兼容 re 模块的同时,支持了一些新特性。由于实现方案的不同,也没有很明确的文档阐述,尚不清楚它具体的算法(有待进一步从代码层面解读),但是从效果上,它的性能要略好于原生模块,仅从文中里例子测试看来,也规避了性能陷阱,可以谨慎采用。
总结
- 和很多其他场景一样,程序需要时刻警惕用户的输入,任何不经过校验的内容都可能将程序拖垮。
- 理论和实际存在各种各样的鸿沟,在面临现实场景时,理想的想法落地总是困难的。
- 原生不代表就是最优秀的。有特殊需求时可以使用社区方案进行替换。
参考:
- https://swtch.com/~rsc/regexp/regexp1.html
- https://owasp.org/www-community/attacks/Regular_expression_Denial_of_Service_-_ReDoS
- https://shivankaul.com/blog/nfa-dfa-and-regexes
- https://arstechnica.com/civis/viewtopic.php?f=20&t=1195549
- https://news.ycombinator.com/item?id=466957
- https://medium.com/swlh/visualizing-thompsons-construction-algorithm-for-nfas-step-by-step-f92ef378581b