😶🌫️ 全文以后端开发视角写作,部分涉及到前端开发的介绍可能存在错误或者不准确,欢迎在评论区斧正
什么是 GraphQL ?
先来看看 wikipedia:
GraphQL 是一个开源的,面向 API 而创造出来的数据查询操作语言以及相应的服务端运行环境。
GraphQL 首先是一种查询语言,它定义了一种通用的数据查询方式,可以理解为一种通用的 SQL,只不过前者面向抽象的数据集,后者往往是具体的关系型数据库。
其次,它还包括一种服务端运行时,用于实现查询语句解析、数据类型定义。
它有什么有意思的特性
仅从后端开发视角,列举几个觉得有意思的特性
Fragments
1 | query HeroComparison($first: Int = 3) { |
使用 Fragment 复用查询内容,并且可以定义参数
Directives
1 | query Hero($episode: Episode, $withFriends: Boolean!) { |
可以通过通用的两种指令来控制一些字段的返回:
@include(if: Boolean)@skip(if: Boolean)
和 REST 相比较有什么优势和劣势?
TLDR
REST 更多是从 HTTP 协议出发的一种约定协议,因为受制于 HTTP 协议本身的设计,在表达能力上是弱于作为查询语言的 GraphQL 的。
同时,REST 通常都是由后端开发者主动封装,而 GraphQL 则是由前端主动拼装。
所以如果面对的场景是前端需求复杂而多变,GraphQL 肯定比 REST 更适合快速迭代。
也正因此,GraphQL 在实现上更加繁复,所以面对 API 数量少、需求不会轻易的场景时,REST 反而是更适合的技术选型。
*作为后端开发,学习和使用 GraphQL 的动力,更多是**想将自己从 CRUD 的泥沼中拯救出来,*将更多的精力放在其他更重要的技术上。
vs 扩展的 REST 协议
(此小节中图片拷贝自网络,懒得画)
和 REST 一样,GraphQL 并不是什么开发框架,它只是定义了一种通用型查询的 DSL。
而使用 REST 协议进行资源拉取,我们总是会面临一些实际的问题,而 GraphQL 可以在一定程度上解决。那么肯定会有同学在想,REST 是非常灵活的,完全可以通过自建一个查询语法,弥补上述的 REST 缺陷,何必要另外引入 GraphQL 徒增复杂度呢。
说的没错,所以我们在阐述这些问题的时候,也会附上我们当前基于 REST 的解决方案。
Overfetching:
假如我们定义了一个 /comments 的 API,输出评论列表。以 django-rest-framework 为例,我们都会定义一个 Serializer 来声明它的输入和输出。
1 | from rest_framework import serializers |
看起来符合常理,它可以轻松满足大多数评论列表的需求。但是也许某一天,我们需要一个评论的精简列表的 API,当前返回内容中,除了 content 以外的其他字段都变成多余了,那么后端开发需要重新定一个 MinimalCommentSerializer 来满足新的需求。
在 REST 基础中,我们增加了 fields 参数,并在 DRF Serializer 里做了特殊处理(你可以点击查看源码),实现的具体效果:
1 | # 查询 comment,并限制结果返回字段 |
而如果我们使用 GraphQL,写法上会更自然:
1 | query { |
Underfetching
相较于 Overfetching 是获取了过多数据,Underfetching 则是在请求获取的数据不足够满足需求。
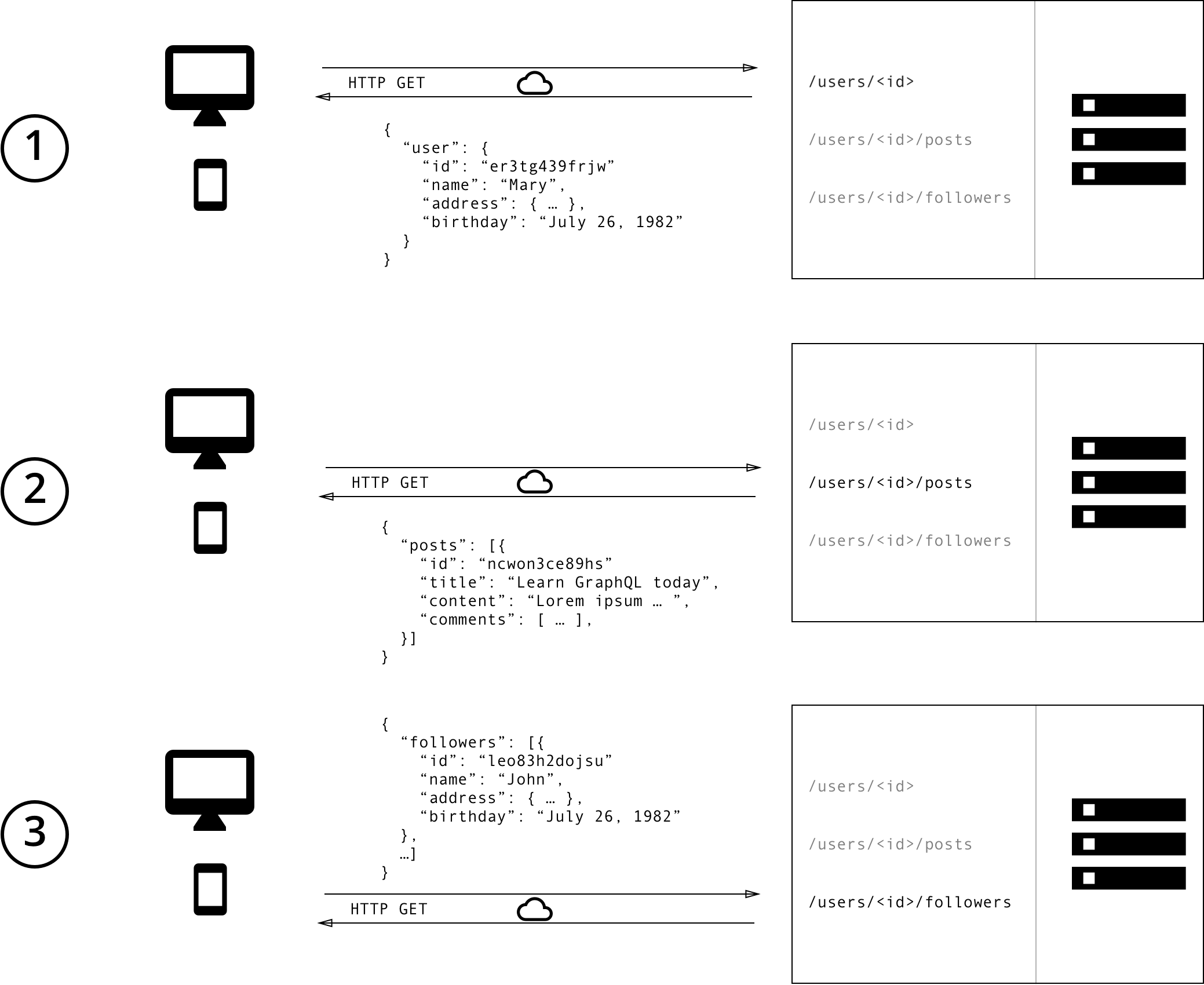
传统的 REST 协议
假如我们需要获取所有用户维度的评论,我们需要先获取通过 /users 所有用户 id,再使用 id 列表遍历查询 /users/<id>/comments 来获取相关的列表。
在 REST 中,为了这个需求我们可能会额外为 /users 增加一个参数 with_comments
1 | # 查询 users,并限制结果返回字段 |
相较于自定义的 REST 协议,使用 GraphQL 可以更简单:
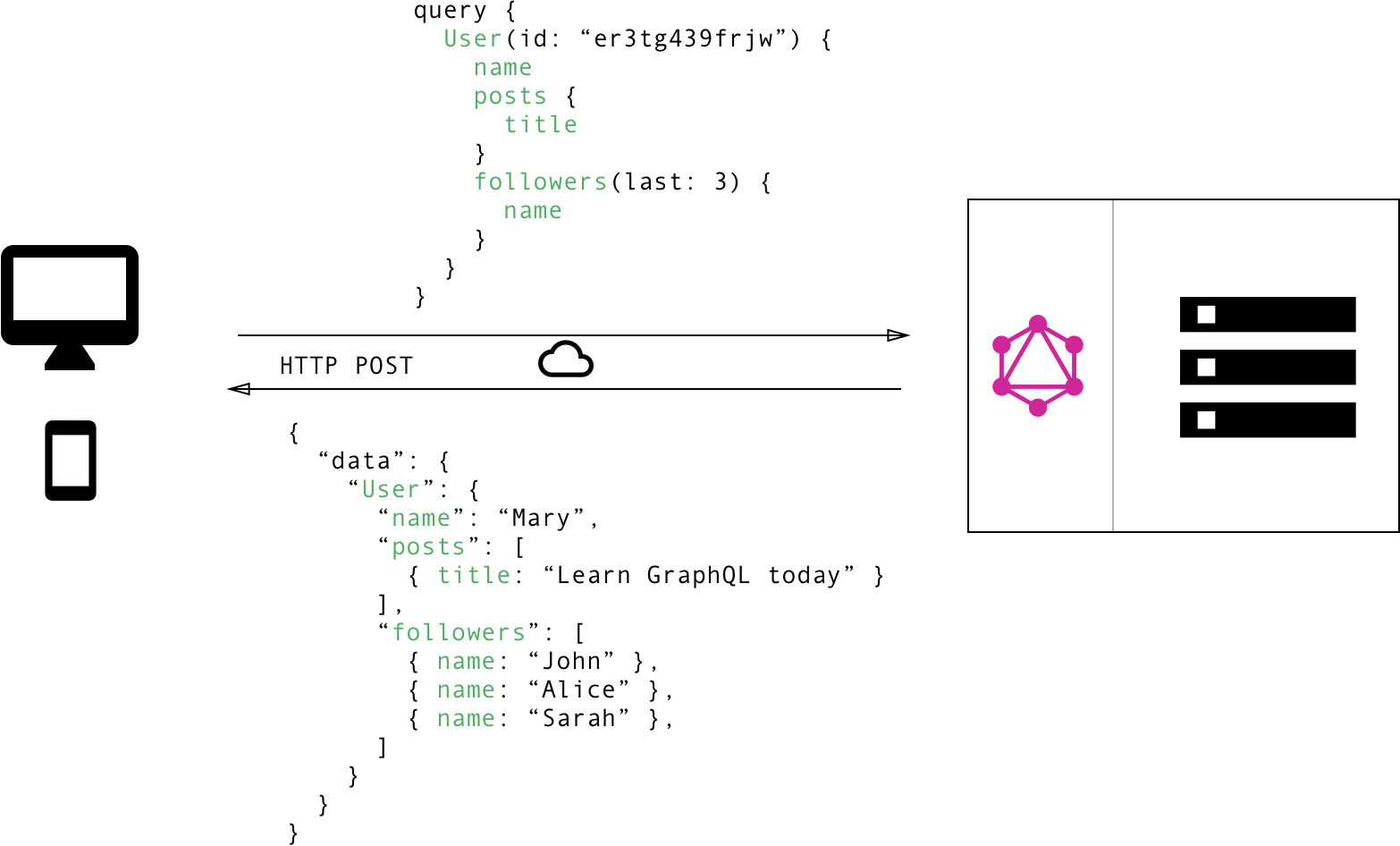
使用 GraphQL,只需要一次请求
相信通过上面的例子,我们可以清晰地看出,相较于 GraphQL ,基于 REST 扩展协议存在这些问题:
- 不够通用,用户有额外的学习成本,增加了额外的文档负担。
- 基于 REST ,单个请求只能针对单个对象进行描述。需要等待需求沉淀,由后端主动封装,迭代节奏会更慢。
什么是 GraphQL 客户端?
我们主要聚焦于 GraphQL 服务端提供,但是也需要先看一下所谓的客户端究竟做了什么。
简单来说,要想在原生 Javascript 中直接使用 GraphQL 并不是一件特别容易的事,需要一些库来协助拉取和管理 GraphQL 数据。
相较于原生的 GraphQL ,客户端主要解决了几件事情:
- 客户端数据拉取缓存问题(包括缓存一致性、更新缓存等)
- 数据分页、声明式数据获取
- …
主流的客户端框架主要有两种—— Relay 和 Apollo ,我们仅从有限的角度来看下二者的异同:
| Relay | Apollo | |
|---|---|---|
| 框架支持 | 仅支持 React, React Native | 无框架限定 |
| GraphQL API | 需要特定的 Schema 支持 | 无需特定的 Schema 支持 |
| 学习成本 | 较高 | 较低 |
| 生产力 | 高 | 较低 |
| 灵活性 | 固定结构 | 较灵活 |
| 是否支持订阅 | 否 | 是 |
| 简而言之,Realy 更复杂,更能够应对大型应用,Apollo 更轻量,不过需要更多的手工劳动。 |
服务端落地:GraphQL → Django
想要将 GraphQL 引入现有的项目,我们需要安装两个基础的依赖:
二者分别负责两部分的工作:
- Django Model ⇒ Schema
- Query ⇒ Filter Django Model
支持 Relay
graphene-django 本身 默认支持 Relay,所以你可以很容易地开启
1 | from graphene import relay |
不过很多时候考虑到 Relay 的复杂度,有时都不适合引入,更何况 Relay 需要特殊的 Schema 支持:
1 | query { |
1 | query { |
这时候 graphene-django 就存在一个问题,当不使用 Relay 时,存在一些功能缺失:
- Fragment \ Directives
- 分页、过滤
- 通过 DRF Serializer 定义 Mutations
所以我们需要引入额外的库来解决。
引入 graphene-django-extras
1 | from graphene import ObjectType |
支持复杂过滤查询
可以在列表对象中增加 filter_fields ,针对不同的字段支持不同的 Django 复杂查询方法。
1 | class CommentListType(DjangoListObjectType): |
这样就可以将一些 Django 的查询能力释放到前端
1 | query { |
自定义查询字段
Django 默认的查询能力,对于一些特殊字段并不能完全覆盖需求,这时我们就需要针对这些内容手写一些处理逻辑。
1 | class Query(ObjectType): |
需要注意的是,当我们使用 resolve_ 函数去处理查询时,GraphQL 和 REST 本质上只是查询 DSL 有所区别,都会遇到类似像 N+1 这样的慢查询问题,所以需要谨慎地将前端的查询转换成可靠的 Django ORM 查询。
鉴权
由于 API 请求并不再经过传统封装的 ViewSet,原有的鉴权组件不再能使用,你需要引入新的 graphene-permissions 来解决针对用户的权限控制。
本文成文时,graphene-permissions 对于最新的 Graphene 3.x 有一些小的兼容性问题,由于该库代码量非常小,可以考虑复制到自己的项目手动维护。
1 | from .mixins import AuthNode |
尴尬的是,如果你并不想用 Relay,我们需要针对 graphene-django-extras 做一些自己的定制,而原有的封装没有很好地暴露足够的接口,经过一番探索并无头绪,最终作罢🥴。
总结
- GraphQL 在前端需求迭代频繁的场景下,比 REST 更符合现代开发节奏
- GraphQL 的语言设计比自定义扩展的 REST 更自然,更具备通用性
- GraphQL 会将比较多的工作放到客户端,适合成熟的客户端开发团队,反之 REST 是更好的选择
- Django 相关的生态建设并不完善,没有一个足够强大、开箱即用的整合方案
- 由于查询并不是基于 Uri 维度,会给周边配套的生态—— 监控、日志等 ——带来一些新的挑战