前情提要
一直以来,我们在 Python 项目中的后台任务都是使用 celery 搭配 Redis(作为 broker)来完成,同时针对短任务轮询场景我们也做了一些封装。在项目运行的三~四年间,这套方案完美地承载了我们核心功能。
然而,就在不久前的一周,出现一些比较诡异的问题,总是有些后台任务发生阻塞,我们使用的多种异常观测手段(Sentry、日志等)都无法准确定位到具体问题(这或许是另一个故事),于是死马当活马医,我们决定将 Redis 更换为 RabbitMQ,这样能够更为准确地观测到任务具体执行的消息情况(例如是否及时Ack)。
案发现场
更换完 broker 之后,却发现了另一个奇怪的问题(没错,这才是本文的主角)。我们在某一些特殊资源的场景下,celery 任务会直接报错:
1 | ConnectionResetError: [Errno 104] Connection reset by peer |
由于我们使用了一层 CLB 作为高可用代理,而之前的使用经验中,CLB 可能会有一些长时间无数据断连的情况,所以我们暂时认为可能是某些长时间的阻塞任务会导致 CLB 主动断开,为了排除干扰,我们甩开了 CLB,直接采用 MQ 的多个节点作为地址直连。
然而,问题依旧,一时间又没了头绪,我开始漫无目的重新浏览 Sentry 中的错误堆栈以及相关变量。
蛛丝马迹
无意间,发现在代码中,我们尝试向队列中存储一大段 pickle 过的对象数据,而这些变量在 Sentry 中已经长到无法完整显示而被省略了。
1 | ... |
这个问题立马引起了我们的注意🤔,很有可能是这个数据过大而引起写入异常。
破案
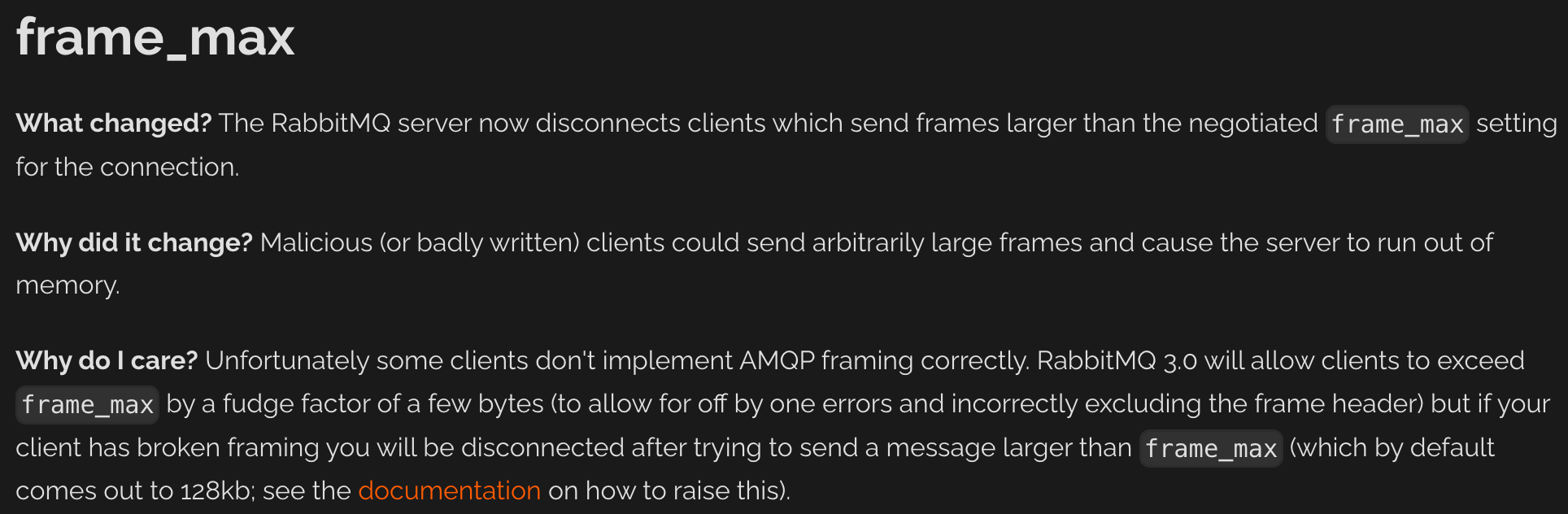
照此思路,经过一番网络冲浪,发现了类似的问题:
这时候,再去反查 RabbitMQ 的日志,果然有对应内容:
1 | 2021-11-16 19:49:32.098 [error] <0.3894.1636> Error on AMQP connection <0.3894.1636> (x.x.x.x:59823 -> x.x.x.x:5672, vhost: 'foo', user: 'foo', state: running), channel 1: |
这里非常明确地指出了,由于我们传递的 frame 大小(245629 bytes) 大于默认的 131064 + 8(frame header) bytes (128KB),所以 RabbitMQ 关闭了连接。
于是我们立即着手,精简了向 headers 传送的数据,重新发布后,终于一切归于正常。
梳理
虽然问题已经得到了解决,但是仍旧需要补齐一下相关知识的短板。
首先,让我们再来简单看看 AMQP 0.9.1 版本 协议有关这部分的内容。
AMQP 协议
这是协议中所有 TCP/IP 帧组成
1 | 0 1 3 7 size+7 size+8 |
其中有这么几个关键信息:
- 0-7 bytes 确定了帧的类型和具体的 channel,确定了类型后将会处理 payload
- payload 的大小在协议中并没有规定,而是说的是可以通过客户端和服务端的”协商“确定(page 22)
- 不同类型帧有着不同的 payload 构成
当前问题主要是传递应用数据的场景下,所以我们来看具体承载的 Content 帧
简单点来说,Content 帧就是一系列的 properties 加上二进制的数据部分。这些 properties 将会组成 “content header frame”,它大概是这样的组成:
1 | 0 2 4 12 14 |
也就是在我们的 celery 代码中, headers=(...) 传递的内容将会被塞入 property list 中,在协议中并没有明确具体的大小限制,同时没有表明会做的分块(content body 部分是会的),所以当前产生的问题限制,主要受制于 RabbitMQ 的具体实现。
https://blog.rabbitmq.com/posts/2012/11/breaking-things-with-rabbitmq-3-0/
三点感悟
- 错误监测非常重要。如果没有 Sentry,问题的定位可能会更加困难,多耗几天精力也未可知。
- 要善于利用不同组件的优势。之所以一开始使用 Redis 而不是 RabbitMQ,更多是从运营维护的角度出发,在公司内部 Redis 有更完善的基建基础,而 RabbitMQ 的运维更加复杂。但是遇到像这样幽灵般的问题时,RabbitMQ 反而更有优势,完善的流程更容易暴露问题。
- 要适当地了解重点依赖的技术细节。大多数场景下,简单地使用协议就足够了,而在一些边缘场景中,则更看重技术人员对细节的把控。这类属于重要不紧急的事情,应该定时拿出来有意识去做,虽无近用,却有远益。
参考: